
Yann Neuhaus

CloudNativePG – Scaling up and down
By now, if you followed the previous posts (here, here, here, here and here), we know quite a bit about how to use CloudNativePG to deploy a PostgreSQL cluster and how to get detailed information about the deployment. What we’ll look at in this post is how you can leverage this deployment to scale the cluster up and down. This might be important if you have changing workloads throughout the day or the week and your application is able to distribute read only workloads across the PostgreSQL replicas.
When we look at what we have now, we do see this:
minicube@micro-minicube:~> kubectl-cnpg status my-pg-cluster
Cluster Summary
Name: my-pg-cluster
Namespace: default
System ID: 7378131726640287762
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:16.2
Primary instance: my-pg-cluster-1
Primary start time: 2024-06-08 13:59:26 +0000 UTC (uptime 88h35m7s)
Status: Cluster in healthy state
Instances: 3
Ready instances: 3
Current Write LSN: 0/26000000 (Timeline: 1 - WAL File: 000000010000000000000012)
Certificates Status
Certificate Name Expiration Date Days Left Until Expiration
---------------- --------------- --------------------------
my-pg-cluster-ca 2024-09-06 13:54:17 +0000 UTC 86.31
my-pg-cluster-replication 2024-09-06 13:54:17 +0000 UTC 86.31
my-pg-cluster-server 2024-09-06 13:54:17 +0000 UTC 86.31
Continuous Backup status
Not configured
Physical backups
No running physical backups found
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------
my-pg-cluster-2 0/26000000 0/26000000 0/26000000 0/26000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
my-pg-cluster-3 0/26000000 0/26000000 0/26000000 0/26000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
Unmanaged Replication Slot Status
No unmanaged replication slots found
Managed roles status
No roles managed
Tablespaces status
No managed tablespaces
Pod Disruption Budgets status
Name Role Expected Pods Current Healthy Minimum Desired Healthy Disruptions Allowed
---- ---- ------------- --------------- ----------------------- -------------------
my-pg-cluster replica 2 2 1 1
my-pg-cluster-primary primary 1 1 1 0
Instances status
Name Database Size Current LSN Replication role Status QoS Manager Version Node
---- ------------- ----------- ---------------- ------ --- --------------- ----
my-pg-cluster-1 37 MB 0/26000000 Primary OK BestEffort 1.23.1 minikube
my-pg-cluster-2 37 MB 0/26000000 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-3 37 MB 0/26000000 Standby (async) OK BestEffort 1.23.1 minikube
We have a primary instance running in pod my-pg-cluster-1, and we have two replicas in asynchronous mode running in pods my-pg-cluster-2 and my-pg-cluster-3. Let’s assume we have an increasing workload and we want to have two more replicas. There are two ways in which you can do this. The first one is to change the configuration of the cluster in the yaml and then re-apply the configuration. This is the configuration as it is now:
apiVersion: postgresql.cnpg.io/v1
kind: Cluster
metadata:
name: my-pg-cluster
spec:
instances: 3
bootstrap:
initdb:
database: db1
owner: db1
dataChecksums: true
walSegmentSize: 32
localeCollate: 'en_US.utf8'
localeCType: 'en_US.utf8'
postInitSQL:
- create user db2
- create database db2 with owner = db2
postgresql:
parameters:
work_mem: "12MB"
pg_stat_statements.max: "2500"
pg_hba:
- host all all 192.168.122.0/24 scram-sha-256
storage:
size: 1Gi
All we need to do is to change the number of instances we want to have. With the current value of three, we get one primary and two replicas. If we want to have two more replicas, change this to five and re-apply:
minicube@micro-minicube:~> grep instances pg.yaml
instances: 5
minicube@micro-minicube:~> kubectl apply -f pg.yaml
cluster.postgresql.cnpg.io/my-pg-cluster configured
By monitoring the pods you can follow the progress of bringing up two new pods and attaching the replicas to the current cluster:
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (32m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (32m ago) 2d
my-pg-cluster-3 1/1 Running 1 (32m ago) 2d
my-pg-cluster-4 0/1 PodInitializing 0 3s
my-pg-cluster-4-join-kqgwp 0/1 Completed 0 11s
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (33m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (33m ago) 2d
my-pg-cluster-3 1/1 Running 1 (33m ago) 2d
my-pg-cluster-4 1/1 Running 0 42s
my-pg-cluster-5 1/1 Running 0 19s
Now we see five pods, as requested, and looking at the PostgreSQL streaming replication configuration confirms that we now have four replicas:
minicube@micro-minicube:~> kubectl-cnpg status my-pg-cluster
Cluster Summary
Name: my-pg-cluster
Namespace: default
System ID: 7378131726640287762
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:16.2
Primary instance: my-pg-cluster-1
Primary start time: 2024-06-08 13:59:26 +0000 UTC (uptime 88h43m54s)
Status: Cluster in healthy state
Instances: 5
Ready instances: 5
Current Write LSN: 0/2C000060 (Timeline: 1 - WAL File: 000000010000000000000016)
Certificates Status
Certificate Name Expiration Date Days Left Until Expiration
---------------- --------------- --------------------------
my-pg-cluster-ca 2024-09-06 13:54:17 +0000 UTC 86.30
my-pg-cluster-replication 2024-09-06 13:54:17 +0000 UTC 86.30
my-pg-cluster-server 2024-09-06 13:54:17 +0000 UTC 86.30
Continuous Backup status
Not configured
Physical backups
No running physical backups found
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------
my-pg-cluster-2 0/2C000060 0/2C000060 0/2C000060 0/2C000060 00:00:00 00:00:00 00:00:00 streaming async 0 active
my-pg-cluster-3 0/2C000060 0/2C000060 0/2C000060 0/2C000060 00:00:00 00:00:00 00:00:00 streaming async 0 active
my-pg-cluster-4 0/2C000060 0/2C000060 0/2C000060 0/2C000060 00:00:00 00:00:00 00:00:00 streaming async 0 active
my-pg-cluster-5 0/2C000060 0/2C000060 0/2C000060 0/2C000060 00:00:00 00:00:00 00:00:00 streaming async 0 active
Unmanaged Replication Slot Status
No unmanaged replication slots found
Managed roles status
No roles managed
Tablespaces status
No managed tablespaces
Pod Disruption Budgets status
Name Role Expected Pods Current Healthy Minimum Desired Healthy Disruptions Allowed
---- ---- ------------- --------------- ----------------------- -------------------
my-pg-cluster replica 4 4 3 1
my-pg-cluster-primary primary 1 1 1 0
Instances status
Name Database Size Current LSN Replication role Status QoS Manager Version Node
---- ------------- ----------- ---------------- ------ --- --------------- ----
my-pg-cluster-1 37 MB 0/2C000060 Primary OK BestEffort 1.23.1 minikube
my-pg-cluster-2 37 MB 0/2C000060 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-3 37 MB 0/2C000060 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-4 37 MB 0/2C000060 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-5 37 MB 0/2C000060 Standby (async) OK BestEffort 1.23.1 minikube
If you want to scale this down again (maybe because the workload decreased), you can do that in the same way by reducing the number of instances from five to three in the cluster definition, or by directly scaling the cluster down with kubectl:
minicube@micro-minicube:~> kubectl scale --replicas=2 -f pg.yaml
cluster.postgresql.cnpg.io/my-pg-cluster scaled
Attention: Replicas in this context does not mean streaming replication replicas. It means replicas in the context of Kubernetes, so if you do it like above, the result will be one primary and one replica:
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (39m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (39m ago) 2d1h
What you probably really want is this (to get back to the initial state of the cluster):
minicube@micro-minicube:~> kubectl scale --replicas=3 -f pg.yaml
cluster.postgresql.cnpg.io/my-pg-cluster scaled
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (41m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (41m ago) 2d1h
my-pg-cluster-6-join-747nx 0/1 Pending 0 1s
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (41m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (41m ago) 2d1h
my-pg-cluster-6-join-747nx 1/1 Running 0 5s
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (42m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (42m ago) 2d1h
my-pg-cluster-6 0/1 Running 0 5s
my-pg-cluster-6-join-747nx 0/1 Completed 0 14s
...
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 1 (42m ago) 2d1h
my-pg-cluster-2 1/1 Running 1 (42m ago) 2d1h
my-pg-cluster-6 1/1 Running 0 16s
What you shouldn’t do is to mix both ways of scaling, for one reason: If you scale up or down by using “kubectl scale”, this will not modify your cluster configuration file. There we still have five instances:
minicube@micro-minicube:~> grep instances pg.yaml
instances: 5
Our recommendation is, to do this only by modifying the configuration and re-apply afterwards. This ensures, that you always have the “reality” in the configuration file, and not a mix of live state and desired state.
In the next we’ll look into storage, because you want your databases to be persistent and fast.
L’article CloudNativePG – Scaling up and down est apparu en premier sur dbi Blog.
CloudNativePG – The kubectl plugin
As we’re getting more and more familiar with CloudNativePG, now it’s time to get more information about our cluster, either for monitoring or troubleshooting purposes. Getting information about the general state of our cluster can be easily done by using kubectl.
For listing the global state of our cluster, you can do:
minicube@micro-minicube:~> kubectl get cluster -A
NAMESPACE NAME AGE INSTANCES READY STATUS PRIMARY
default my-pg-cluster 41h 3 3 Cluster in healthy state my-pg-cluster-1
As we’ve seen in the previous posts (here, here, here and here) kubectl can also be used to get information about the pods and services of the deployment:
minicube@micro-minicube:~> kubectl get pods
NAME READY STATUS RESTARTS AGE
my-pg-cluster-1 1/1 Running 0 108m
my-pg-cluster-2 1/1 Running 0 103m
my-pg-cluster-3 1/1 Running 0 103m
minicube@micro-minicube:~> kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
kubernetes ClusterIP 10.96.0.1 <none> 443/TCP 4d
my-pg-cluster-r ClusterIP 10.111.113.4 <none> 5432/TCP 41h
my-pg-cluster-ro ClusterIP 10.110.137.246 <none> 5432/TCP 41h
my-pg-cluster-rw ClusterIP 10.100.77.15 <none> 5432/TCP 41h
What we cannot see easily with kubectl is information related to PostgreSQL itself. But as kubectl can be extended with plugins, CloudNativePG comes with a plugin for kubectl which is called “cnpg“. There are several installation methods available, we’ll go for the scripted version:
minicube@micro-minicube:~> curl -sSfL https://github.com/cloudnative-pg/cloudnative-pg/raw/main/hack/install-cnpg-plugin.sh | sudo sh -s -- -b /usr/local/bin
cloudnative-pg/cloudnative-pg info checking GitHub for latest tag
cloudnative-pg/cloudnative-pg info found version: 1.23.1 for v1.23.1/linux/x86_64
cloudnative-pg/cloudnative-pg info installed /usr/local/bin/kubectl-cnpg
A very nice feature of this plugin is, that it comes with support for auto completion of the available commands, but this needs to be configured before you can use it. You can use the plugin itself to generate the completion script for one of the supported shells (bash in my case):
minicube@micro-minicube:~> kubectl cnpg completion
Generate the autocompletion script for kubectl-cnpg for the specified shell.
See each sub-command's help for details on how to use the generated script.
Usage:
kubectl cnpg completion [command]
Available Commands:
bash Generate the autocompletion script for bash
fish Generate the autocompletion script for fish
powershell Generate the autocompletion script for powershell
zsh Generate the autocompletion script for zsh
...
minicube@micro-minicube:~> kubectl cnpg completion bash > kubectl_complete-cnpg
minicube@micro-minicube:~> chmod +x kubectl_complete-cnpg
minicube@micro-minicube:~> sudo mv kubectl_complete-cnpg /usr/local/bin/
From now, tab completion is working:
minicube@micro-minicube:~> kubectl-cnpg [TAB][TAB]
backup (Request an on-demand backup for a PostgreSQL Cluster)
certificate (Create a client certificate to connect to PostgreSQL using TLS and Certificate authentication)
completion (Generate the autocompletion script for the specified shell)
destroy (Destroy the instance named [cluster]-[node] or [node] with the associated PVC)
fencing (Fencing related commands)
fio (Creates a fio deployment, pvc and configmap)
help (Help about any command)
hibernate (Hibernation related commands)
install (CNPG installation commands)
logs (Collect cluster logs)
maintenance (Sets or removes maintenance mode from clusters)
pgadmin4 (Creates a pgadmin deployment)
pgbench (Creates a pgbench job)
promote (Promote the pod named [cluster]-[node] or [node] to primary)
psql (Start a psql session targeting a CloudNativePG cluster)
publication (Logical publication management commands)
reload (Reload the cluster)
report (Report on the operator)
restart (Restart a cluster or a single instance in a cluster)
snapshot (command removed)
status (Get the status of a PostgreSQL cluster)
subscription (Logical subscription management commands)
version (Prints version, commit sha and date of the build)
As you can see, quite a few commands are available, but for the scope of this post, we’ll only use the commands for getting logs and detailed information about our cluster. Obviously the “status” command should give us some global information about the cluster, and actually it will give us much more:
minicube@micro-minicube:~> kubectl-cnpg status my-pg-cluster
Cluster Summary
Name: my-pg-cluster
Namespace: default
System ID: 7378131726640287762
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:16.2
Primary instance: my-pg-cluster-1
Primary start time: 2024-06-08 13:59:26 +0000 UTC (uptime 42h49m23s)
Status: Cluster in healthy state
Instances: 3
Ready instances: 3
Current Write LSN: 0/1E000000 (Timeline: 1 - WAL File: 00000001000000000000000E)
Certificates Status
Certificate Name Expiration Date Days Left Until Expiration
---------------- --------------- --------------------------
my-pg-cluster-ca 2024-09-06 13:54:17 +0000 UTC 88.21
my-pg-cluster-replication 2024-09-06 13:54:17 +0000 UTC 88.21
my-pg-cluster-server 2024-09-06 13:54:17 +0000 UTC 88.21
Continuous Backup status
Not configured
Physical backups
No running physical backups found
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ----------------
my-pg-cluster-2 0/1E000000 0/1E000000 0/1E000000 0/1E000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
my-pg-cluster-3 0/1E000000 0/1E000000 0/1E000000 0/1E000000 00:00:00 00:00:00 00:00:00 streaming async 0 active
Unmanaged Replication Slot Status
No unmanaged replication slots found
Managed roles status
No roles managed
Tablespaces status
No managed tablespaces
Pod Disruption Budgets status
Name Role Expected Pods Current Healthy Minimum Desired Healthy Disruptions Allowed
---- ---- ------------- --------------- ----------------------- -------------------
my-pg-cluster replica 2 2 1 1
my-pg-cluster-primary primary 1 1 1 0
Instances status
Name Database Size Current LSN Replication role Status QoS Manager Version Node
---- ------------- ----------- ---------------- ------ --- --------------- ----
my-pg-cluster-1 37 MB 0/1E000000 Primary OK BestEffort 1.23.1 minikube
my-pg-cluster-2 37 MB 0/1E000000 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-3 37 MB 0/1E000000 Standby (async) OK BestEffort 1.23.1 minikube
This is quite some amount of information and tells us a lot about our cluster, including:
- We have one primary node and two replicas in asynchronous replication (this comes from the three instances we specified in the cluster configuration)
- All instances are healthy and there is no replication lag
- The version of PostgreSQL is 16.2
- The configuration is using replication slots
- Information about the certificates used for encrypted traffic
- We do not have configured any backups (this will be the topic of one of the next posts)
If you want too see even more information, including e.g. the configuration of PostgreSQL, pass the “–verbose” flag to the status command:
minicube@micro-minicube:~> kubectl-cnpg status my-pg-cluster --verbose
Cluster Summary
Name: my-pg-cluster
Namespace: default
System ID: 7378131726640287762
PostgreSQL Image: ghcr.io/cloudnative-pg/postgresql:16.2
Primary instance: my-pg-cluster-1
Primary start time: 2024-06-08 13:59:26 +0000 UTC (uptime 42h57m30s)
Status: Cluster in healthy state
Instances: 3
Ready instances: 3
Current Write LSN: 0/20000110 (Timeline: 1 - WAL File: 000000010000000000000010)
PostgreSQL Configuration
archive_command = '/controller/manager wal-archive --log-destination /controller/log/postgres.json %p'
archive_mode = 'on'
archive_timeout = '5min'
cluster_name = 'my-pg-cluster'
dynamic_shared_memory_type = 'posix'
full_page_writes = 'on'
hot_standby = 'true'
listen_addresses = '*'
log_destination = 'csvlog'
log_directory = '/controller/log'
log_filename = 'postgres'
log_rotation_age = '0'
log_rotation_size = '0'
log_truncate_on_rotation = 'false'
logging_collector = 'on'
max_parallel_workers = '32'
max_replication_slots = '32'
max_worker_processes = '32'
pg_stat_statements.max = '2500'
port = '5432'
restart_after_crash = 'false'
shared_memory_type = 'mmap'
shared_preload_libraries = 'pg_stat_statements'
ssl = 'on'
ssl_ca_file = '/controller/certificates/client-ca.crt'
ssl_cert_file = '/controller/certificates/server.crt'
ssl_key_file = '/controller/certificates/server.key'
ssl_max_protocol_version = 'TLSv1.3'
ssl_min_protocol_version = 'TLSv1.3'
unix_socket_directories = '/controller/run'
wal_keep_size = '512MB'
wal_level = 'logical'
wal_log_hints = 'on'
wal_receiver_timeout = '5s'
wal_sender_timeout = '5s'
work_mem = '12MB'
cnpg.config_sha256 = 'db8a255b574978eb43a479ec688a1e8e72281ec3fa03b59bcb3cf3bf9b997e67'
PostgreSQL HBA Rules
#
# FIXED RULES
#
# Grant local access ('local' user map)
local all all peer map=local
# Require client certificate authentication for the streaming_replica user
hostssl postgres streaming_replica all cert
hostssl replication streaming_replica all cert
hostssl all cnpg_pooler_pgbouncer all cert
#
# USER-DEFINED RULES
#
host all all 192.168.122.0/24 scram-sha-256
#
# DEFAULT RULES
#
host all all all scram-sha-256
Certificates Status
Certificate Name Expiration Date Days Left Until Expiration
---------------- --------------- --------------------------
my-pg-cluster-ca 2024-09-06 13:54:17 +0000 UTC 88.21
my-pg-cluster-replication 2024-09-06 13:54:17 +0000 UTC 88.21
my-pg-cluster-server 2024-09-06 13:54:17 +0000 UTC 88.21
Continuous Backup status
Not configured
Physical backups
No running physical backups found
Streaming Replication status
Replication Slots Enabled
Name Sent LSN Write LSN Flush LSN Replay LSN Write Lag Flush Lag Replay Lag State Sync State Sync Priority Replication Slot Slot Restart LSN Slot WAL Status Slot Safe WAL Size
---- -------- --------- --------- ---------- --------- --------- ---------- ----- ---------- ------------- ---------------- ---------------- --------------- ------------------
my-pg-cluster-2 0/20000110 0/20000110 0/20000110 0/20000110 00:00:00 00:00:00 00:00:00 streaming async 0 active 0/20000110 reserved NULL
my-pg-cluster-3 0/20000110 0/20000110 0/20000110 0/20000110 00:00:00 00:00:00 00:00:00 streaming async 0 active 0/20000110 reserved NULL
Unmanaged Replication Slot Status
No unmanaged replication slots found
Managed roles status
No roles managed
Tablespaces status
No managed tablespaces
Pod Disruption Budgets status
Name Role Expected Pods Current Healthy Minimum Desired Healthy Disruptions Allowed
---- ---- ------------- --------------- ----------------------- -------------------
my-pg-cluster replica 2 2 1 1
my-pg-cluster-primary primary 1 1 1 0
Instances status
Name Database Size Current LSN Replication role Status QoS Manager Version Node
---- ------------- ----------- ---------------- ------ --- --------------- ----
my-pg-cluster-1 37 MB 0/20000110 Primary OK BestEffort 1.23.1 minikube
my-pg-cluster-2 37 MB 0/20000110 Standby (async) OK BestEffort 1.23.1 minikube
my-pg-cluster-3 37 MB 0/20000110 Standby (async) OK BestEffort 1.23.1 minikube
The other important command when it comes to troubleshooting is the “logs” command (the “-f” is for tail):
minicube@micro-minicube:~> kubectl-cnpg logs cluster my-pg-cluster -f
...
{"level":"info","ts":"2024-06-10T08:51:59Z","logger":"wal-archive","msg":"Backup not configured, skip WAL archiving via Barman Cloud","logging_pod":"my-pg-cluster-1","walName":"pg_wal/00000001000000000000000F","currentPrimary":"my-pg-cluster-1","targetPrimary":"my-pg-cluster-1"}
{"level":"info","ts":"2024-06-10T08:52:00Z","logger":"postgres","msg":"record","logging_pod":"my-pg-cluster-1","record":{"log_time":"2024-06-10 08:52:00.121 UTC","process_id":"1289","session_id":"66669223.509","session_line_num":"4","session_start_time":"2024-06-10 05:41:55 UTC","transaction_id":"0","error_severity":"LOG","sql_state_code":"00000","message":"checkpoint complete: wrote 10 buffers (0.1%); 0 WAL file(s) added, 0 removed, 0 recycled; write=1.005 s, sync=0.006 s, total=1.111 s; sync files=5, longest=0.002 s, average=0.002 s; distance=64233 kB, estimate=64233 kB; lsn=0/20000060, redo lsn=0/1E006030","backend_type":"checkpointer","query_id":"0"}}
{"level":"info","ts":"2024-06-10T08:56:59Z","logger":"wal-archive","msg":"Backup not configured, skip WAL archiving via Barman Cloud","logging_pod":"my-pg-cluster-1","walName":"pg_wal/000000010000000000000010","currentPrimary":"my-pg-cluster-1","targetPrimary":"my-pg-cluster-1"}
This gives you the PostgreSQL as well as the operator logs. Both, the “status” and the “logs” command are essential for troubleshooting.
In the next post we’ll look at scaling the cluster up and down.
L’article CloudNativePG – The kubectl plugin est apparu en premier sur dbi Blog.
How to Fix the etcd Error: “etcdserver: mvcc: database space exceeded” in a Patroni cluster
If you’re encountering the etcd error “etcdserver: mvcc: database space exceeded,” it means your etcd database has exceeded its storage limit. This can occur due to a variety of reasons, such as a large number of revisions or excessive data accumulation. However, there’s no need to panic; this issue can be resolved effectively.
I know that there is already plenty of blogs or posts about etcd, but 99% of them are related to Kubernetes topic where etcd is managed in containers. In my case, etcd cluster is installed on three SLES VMs alongside a Patroni cluster. Using etcd with Patroni enhances the reliability, scalability, and manageability of PostgreSQL clusters by providing a robust distributed coordination mechanism for high availability and configuration management. So dear DBA, I hope that this blog will help you ! Below, I’ll outline the steps to fix this error and prevent this error from happening.
Where did this issue happenThe first time I saw this issue was at a customer. They had a Patroni cluster with 3 nodes, including 2 PostgreSQL instance. They noticed Patroni issue on their monitoring so I was asked to have a look. In the end, the Patroni issue was caused by the etcd database being full. I find the error logs from the etcd service status.
Understanding the ErrorBefore diving into the solution, it’s essential to understand what causes this error. Etcd, a distributed key-value store, utilizes a Multi-Version Concurrency Control (MVCC) model to manage data. When the database space is exceeded, it indicates that there’s too much data stored, potentially leading to performance issues or even service disruptions. By default, the database size is limited to 2Gb, which should be more than enough, but without knowing this limitation, you might encounter the same issue than me one day.
Pause Patroni Cluster ManagementUtilize Patroni’s patronictl command to temporarily suspend cluster management, effectively halting automated failover processes and configuration adjustments while conducting the fix procedure. (https://patroni.readthedocs.io/en/latest/pause.html)
# patronictl pause --wait
'pause' request sent, waiting until it is recognized by all nodes
Success: cluster management is pausedThe first step is to adjust the etcd configuration file to optimize database space usage. Add the following parameters to your etcd configuration file on all nodes of the cluster.
max-wals: 2
auto-compaction-mode: periodic
auto-compaction-retention: "36h"Below, I’ll provide you with some explanation concerning the three parameters we are adding to the configuration file:
- max-wals: 2:
- This parameter specifies the maximum number of write-ahead logs (WALs) that etcd should retain before compacting them. WALs are temporary files used to store recent transactions before they are written to the main etcd database.
- By limiting the number of WALs retained, you control the amount of temporary data stored, which helps in managing disk space usage. Keeping a low number of WALs ensures that disk space is not consumed excessively by temporary transaction logs.
- auto-compaction-mode: periodic:
- This parameter determines the mode of automatic database compaction. When set to “periodic,” etcd automatically compacts its database periodically based on the configured retention period.
- Database compaction removes redundant or obsolete data, reclaiming disk space and preventing the database from growing indefinitely. Periodic compaction ensures that old data is regularly cleaned up, maintaining optimal performance and disk space usage.
- auto-compaction-retention: “36h”:
- This parameter defines the retention period for data before it becomes eligible for automatic compaction. It specifies the duration after which etcd should consider data for compaction.
- In this example, “36h” represents a retention period of 36 hours. Any data older than 36 hours is eligible for compaction during the next periodic compaction cycle.
- Adjusting the retention period allows you to control how long historical data is retained in the etcd database. Shorter retention periods result in more frequent compaction and potentially smaller database sizes, while longer retention periods preserve historical data for a longer duration.
Ensure to restart the etcd service on each node after updating the configuration. You can restart the nodes one by one and monitor the cluster’s status between each restart.
Remove Excessive Data and Defragment the DatabaseExecute various etcd commands to remove excessive data from the etcd database and defragment it. These commands need to be run on each etcd nodes. Complete the whole procedure node by node. In our case, I suggest that we start the process on our third nodes, where we don’t have any PostgreSQL instance running.
# Obtain the current revision
$ rev=$(ETCDCTL_API=3 etcdctl --endpoints=<your-endpoints> endpoint status --write-out="json" | grep -o '"revision":[0-9]*' | grep -o '[0-9].*')
# Compact all old revisions
$ ETCDCTL_API=3 etcdctl compact $rev
# Defragment the excessive space (execute for each etcd node)
$ ETCDCTL_API=3 etcdctl defrag --endpoints=<your-endpoints>
# Disarm alarm
$ ETCDCTL_API=3 etcdctl alarm disarm
# Check the cluster's status again
$ etcdctl endpoint status --cluster -w table
- if the $rev variable contains three times the same number, only use one instance of the number
- The first time you run the compact/defrag commands, you may receive an etcd error. To be on the safe side, run the command on the third node first. In case of an error, you may need to restart the etcd service on the node before continuing. From a blog, this potential error might only concerned etcd version 3.5.x : “There is a known issue that etcd might run into data inconsistency issue if it crashes in the middle of an online defragmentation operation using
etcdctlor clientv3 API. All the existing v3.5 releases are affected, including 3.5.0 ~ 3.5.5. So please useetcdutlto offline perform defragmentation operation, but this requires taking each member offline one at a time. It means that you need to stop each etcd instance firstly, then perform defragmentation usingetcdutl, start the instance at last. Please refer to the issue 1 in public statement.” (https://etcd.io/blog/2023/how_to_debug_large_db_size_issue/#:~:text=Users%20can%20configure%20the%20quota,sufficient%20for%20most%20use%20cases) - Run the defrag command for each node and verify that the DB size has properly reduce each time.
After completing the steps above, ensure there are no more alarms, and the database size has reduced. Monitor the cluster’s performance to confirm that the issue has been resolved successfully.
Resume Patroni Cluster ManagementAfter confirming the successful clean of the alarms, proceed to re-enable cluster management, enabling Patroni to resume its standard operations and exit maintenance mode.
# patronictl resume --wait
'resume' request sent, waiting until it is recognized by all nodes
Success: cluster management is resumedTo conclude, facing the “etcdserver: mvcc: database space exceeded” error can be concerning, but with the right approach, it’s entirely manageable. By updating the etcd configuration and executing appropriate commands to remove excess data and defragment the database, you can optimize your etcd cluster’s performance and ensure smooth operation. Remember to monitor the cluster regularly to catch any potential issues early on. With these steps, you can effectively resolve the etcd database space exceeded error and maintain a healthy etcd environment.
Useful LinksFind more information about etcd database size: How to debug large db size issue?https://etcd.io/blog/2023/how_to_debug_large_db_size_issue/#:~:text=Users%20can%20configure%20the%20quota,sufficient%20for%20most%20use%20cases.
Official etcd operations guide: https://etcd.io/docs/v3.5/op-guide/
L’article How to Fix the etcd Error: “etcdserver: mvcc: database space exceeded” in a Patroni cluster est apparu en premier sur dbi Blog.
Upgrade etcd in a patroni cluster
In a distributed database system like PostgreSQL managed by Patroni, etcd plays a critical role as the distributed key-value store for cluster coordination and configuration. As your system evolves, upgrading etcd becomes necessary to leverage new features, bug fixes, and security enhancements. However, upgrading etcd in a live cluster requires careful planning and execution to ensure data integrity. In this guide, we’ll walk through the process of upgrading etcd from version 3.4.25 to 3.5.12 in a Patroni cluster, based on the detailed notes I took during the upgrade process.
Check the upgrade checklistBefore trying to upgrade, it is important to have a look at all the deprecated features and at the upgrade requirements. In our case, to upgrade to version 3.5.x, it is mandatory that the running cluster is healthy and at least in version 3.4 already.
You can find all this information on the official etcd documentation:
https://etcd.io/docs/v3.3/upgrades/upgrade_3_5/
During the upgrade process, an etcd cluster can accommodate a mix of etcd member versions, functioning based on the protocol of the lowest common version present. The cluster achieves the upgraded status only when all its members are updated to version 3.5. Internally, etcd members negotiate among themselves to establish the overall cluster version, influencing the reported version and the features supported by the cluster.
In most scenarios, transitioning from etcd 3.4 to 3.5 can be accomplished seamlessly through a rolling upgrade process, ensuring zero downtime. Sequentially halt the etcd v3.4 processes, substituting them with etcd v3.5 processes. Upon completion of the migration to v3.5 across all nodes, the enhanced functionalities introduced in v3.5 become accessible to the cluster.
Preparing for the UpgradeBefore starting the upgrade process, it’s essential to make adequate preparations to minimize any potential risks or disruptions. Here are some preliminary steps:
- Check current etcd version
[pgt001] postgres@patroni-1:/postgres/app/postgres> etcdctl version
etcdctl version: 3.4.25
API version: 3.4- Backup etcd data
Use etcdctl to create a snapshot of the etcd data. This ensures that you have a fallback option in case something goes wrong during the upgrade process.
[pgt001] postgres@patroni-1:~> etcdctl snapshot save backup.db
{"level":"info","ts":1710507460.523724,"caller":"snapshot/v3_snapshot.go:119","msg":"created temporary db file","path":"backup.db.part"}
{"level":"info","ts":"2024-03-15T13:57:40.538461+0100","caller":"clientv3/maintenance.go:200","msg":"opened snapshot stream; downloading"}
{"level":"info","ts":1710507460.539052,"caller":"snapshot/v3_snapshot.go:127","msg":"fetching snapshot","endpoint":"127.0.0.1:2379"}
{"level":"info","ts":"2024-03-15T13:57:40.548342+0100","caller":"clientv3/maintenance.go:208","msg":"completed snapshot read; closing"}
{"level":"info","ts":1710507460.5576544,"caller":"snapshot/v3_snapshot.go:142","msg":"fetched snapshot","endpoint":"127.0.0.1:2379","size":"57 kB","took":0.030259485}
{"level":"info","ts":1710507460.5580025,"caller":"snapshot/v3_snapshot.go:152","msg":"saved","path":"backup.db"}
Snapshot saved at backup.db
[pgt001] postgres@patroni-1:~> ll
total 60
-rw------- 1 postgres postgres 57376 Mar 15 13:57 backup.db
[pgt001] postgres@patroni-1:~> etcdctl --write-out=table snapshot status backup.db
+----------+----------+------------+------------+
| HASH | REVISION | TOTAL KEYS | TOTAL SIZE |
+----------+----------+------------+------------+
| 29c96081 | 107 | 117 | 57 kB |
+----------+----------+------------+------------+- Pause Cluster Management
Use Patroni’s patronictl to pause cluster management. This prevents any automated failover or configuration changes during the upgrade process. (https://patroni.readthedocs.io/en/latest/pause.html)
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> patronictl pause --wait
'pause' request sent, waiting until it is recognized by all nodes
Success: cluster management is pausedNow that you’ve prepared your cluster for the upgrade, you can proceed with the actual upgrade steps. All the steps are performed node by node, as mentioned earlier. I will start the upgrade on the third node of my cluster, patroni-3.
- Stop etcd
Stop the etcd service. This ensures that no changes are made to the cluster while the upgrade is in progress.
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> sudo systemctl stop etcd- Extract and Install New etcd Version
Download the new etcd binary and extract it. Then, replace the existing etcd binaries with the new ones.
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> tar axf etcd-v3.5.12-linux-amd64.tar.gz
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> mv etcd-v3.5.12-linux-amd64/etcd* /postgres/app/postgres/local/dmk/bin/
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> etcdctl version
etcdctl version: 3.5.12
API version: 3.5- Start etcd
Start the upgraded etcd service
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> sudo systemctl start etcd
[pg133] postgres@patroni-3:/postgres/app/postgres/local/dmk/bin> sudo systemctl status etcd
● etcd.service - dbi services etcd service
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; preset: enabled)
Active: active (running) since Fri 2024-03-15 14:02:39 CET; 10s ago
Main PID: 1561 (etcd)
Tasks: 9 (limit: 9454)
Memory: 13.1M
CPU: 369ms
CGroup: /system.slice/etcd.service
└─1561 /postgres/app/postgres/local/dmk/bin/etcd --config-file /postgres/app/postgres/local/dmk/etc/etcd.conf
Mar 15 14:02:38 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:38.292751+0100","caller":"etcdserver/server.go:783","msg":"initialized peer connections; fast-forwarding electi>
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.282054+0100","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"raft.node: f1457fc5460d0329 elected>
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.302529+0100","caller":"etcdserver/server.go:2068","msg":"published local member to cluster through raft","lo>
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.302985+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.30307+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.302942+0100","caller":"etcdmain/main.go:44","msg":"notifying init daemon"}
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.303671+0100","caller":"etcdmain/main.go:50","msg":"successfully notified init daemon"}
Mar 15 14:02:39 patroni-3 systemd[1]: Started etcd.service - dbi services etcd service.
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.304964+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
Mar 15 14:02:39 patroni-3 etcd[1561]: {"level":"info","ts":"2024-03-15T14:02:39.305719+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
After each etcd upgrade, it’s always nice to verify the health and functionality of the etcd and Patroni cluster. You can notice from the etcdtcl command that the version was upgraded on the third node.
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> etcdctl endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.56.123:2379 | 90015c533cbf2e84 | 3.4.25 | 61 kB | false | false | 15 | 150 | 150 | |
| http://192.168.56.124:2379 | 9fe85e3cebf257e3 | 3.4.25 | 61 kB | false | false | 15 | 150 | 150 | |
| http://192.168.56.125:2379 | f1457fc5460d0329 | 3.5.12 | 61 kB | true | false | 15 | 150 | 150 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> patronictl list
+ Cluster: pgt001 (7346518467491201916) ----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+----------------+---------+-----------+----+-----------+
| pgt001_1 | 192.168.56.123 | Leader | running | 5 | |
| pgt001_2 | 192.168.56.124 | Replica | streaming | 5 | 0 |
+----------+----------------+---------+-----------+----+-----------+
Maintenance mode: on- Upgrading etcd on the second node of the cluster
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> sudo systemctl stop etcd
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> tar axf etcd-v3.5.12-linux-amd64.tar.gz
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> mv etcd-v3.5.12-linux-amd64/etcd* /postgres/app/postgres/local/dmk/bin/
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> etcdctl version
etcdctl version: 3.5.12
API version: 3.5
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> sudo systemctl start etcd
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> sudo systemctl status etcd
● etcd.service - dbi services etcd service
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; preset: enabled)
Active: active (running) since Fri 2024-03-15 14:04:46 CET; 4s ago
Main PID: 1791 (etcd)
Tasks: 7 (limit: 9454)
Memory: 9.7M
CPU: 295ms
CGroup: /system.slice/etcd.service
└─1791 /postgres/app/postgres/local/dmk/bin/etcd --config-file /postgres/app/postgres/local/dmk/etc/etcd.conf
Mar 15 14:04:45 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:45.690431+0100","caller":"rafthttp/stream.go:274","msg":"established TCP streaming connection with remote peer">
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.739502+0100","logger":"raft","caller":"etcdserver/zap_raft.go:77","msg":"raft.node: 9fe85e3cebf257e3 elected>
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.75204+0100","caller":"etcdserver/server.go:2068","msg":"published local member to cluster through raft","loc>
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.752889+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.753543+0100","caller":"etcdmain/main.go:44","msg":"notifying init daemon"}
Mar 15 14:04:46 patroni-2 systemd[1]: Started etcd.service - dbi services etcd service.
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.754213+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.757187+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.757933+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
Mar 15 14:04:46 patroni-2 etcd[1791]: {"level":"info","ts":"2024-03-15T14:04:46.75994+0100","caller":"etcdmain/main.go:50","msg":"successfully notified init daemon"}
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> patronictl list
+ Cluster: pgt001 (7346518467491201916) ----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+----------------+---------+-----------+----+-----------+
| pgt001_1 | 192.168.56.123 | Leader | running | 5 | |
| pgt001_2 | 192.168.56.124 | Replica | streaming | 5 | 0 |
+----------+----------------+---------+-----------+----+-----------+
Maintenance mode: on
- Upgrading etcd on the third node of the cluster
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> sudo systemctl stop etcdNow that we stopped etcd on the server where is our Patroni leader node, let’s take a look at our patroni cluster status.
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> patronictl list
2024-03-15 14:05:52,778 - ERROR - Failed to get list of machines from http://192.168.56.123:2379/v3beta: MaxRetryError("HTTPConnectionPool(host='192.168.56.123', port=2379): Max retries exceeded with url: /version (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at 0x7f3584365590>: Failed to establish a new connection: [Errno 111] Connection refused'))")
+ Cluster: pgt001 (7346518467491201916) ----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+----------------+---------+-----------+----+-----------+
| pgt001_1 | 192.168.56.123 | Leader | running | 5 | |
| pgt001_2 | 192.168.56.124 | Replica | streaming | 5 | 0 |
+----------+----------------+---------+-----------+----+-----------+
Maintenance mode: on
[pgt001] postgres@patroni-2:/postgres/app/postgres/local/dmk/bin> sq
psql (14.7 dbi services build)
Type "help" for help.
postgres=# exitWe can notice that our Patroni cluster is still up and running and that PostgreSQL cluster is still reachable. Also, thanks to patroni maintenance mode, no failover or configuration changes are happening.
Let’s continue with the installation
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> tar axf etcd-v3.5.12-linux- amd64.tar.gz
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> mv etcd-v3.5.12-linux-amd64 /etcd* /postgres/app/postgres/local/dmk/bin/
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> etcdctl version
etcdctl version: 3.5.12
API version: 3.5
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> sudo systemctl start etcd
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> sudo systemctl status etcd
● etcd.service - dbi services etcd service
Loaded: loaded (/etc/systemd/system/etcd.service; enabled; preset: enabled)
Active: active (running) since Fri 2024-03-15 14:07:12 CET; 3s ago
Main PID: 1914 (etcd)
Tasks: 7 (limit: 9454)
Memory: 15.9M
CPU: 160ms
CGroup: /system.slice/etcd.service
└─1914 /postgres/app/postgres/local/dmk/bin/etcd --config-file /postgres/app/postgres/local/dmk/etc/etcd.conf
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.180191+0100","caller":"etcdserver/server.go:2068","msg":"published local member to cluster through raft","lo>
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.180266+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.181162+0100","caller":"embed/serve.go:103","msg":"ready to serve client requests"}
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.182377+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.182625+0100","caller":"embed/serve.go:187","msg":"serving client traffic insecurely; this is strongly discou>
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.183861+0100","caller":"etcdmain/main.go:44","msg":"notifying init daemon"}
Mar 15 14:07:12 patroni-1 systemd[1]: Started etcd.service - dbi services etcd service.
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.187771+0100","caller":"etcdmain/main.go:50","msg":"successfully notified init daemon"}
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.195369+0100","caller":"membership/cluster.go:576","msg":"updated cluster version","cluster-id":"571a53e78674>
Mar 15 14:07:12 patroni-1 etcd[1914]: {"level":"info","ts":"2024-03-15T14:07:12.195541+0100","caller":"api/capability.go:75","msg":"enabled capabilities for version","cluster-version":"3.5>We now have upgraded etcd on all our nodes and we need to control the status of our clusters.
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> patronictl list
+ Cluster: pgt001 (7346518467491201916) ----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+----------------+---------+-----------+----+-----------+
| pgt001_1 | 192.168.56.123 | Leader | running | 5 | |
| pgt001_2 | 192.168.56.124 | Replica | streaming | 5 | 0 |
+----------+----------------+---------+-----------+----+-----------+
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> etcdctl endpoint status --cluster -w table
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
| http://192.168.56.123:2379 | 90015c533cbf2e84 | 3.5.12 | 61 kB | false | false | 15 | 150 | 150 | |
| http://192.168.56.124:2379 | 9fe85e3cebf257e3 | 3.5.12 | 61 kB | false | false | 15 | 150 | 150 | |
| http://192.168.56.125:2379 | f1457fc5460d0329 | 3.5.12 | 61 kB | true | false | 15 | 150 | 150 | |
+----------------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> etcdctl version
etcdctl version: 3.5.12
API version: 3.5Once you’ve confirmed that the upgrade was successful, resume cluster management to allow Patroni to resume its normal operations and quit maintenance mode.
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> patronictl resume --wait
'resume' request sent, waiting until it is recognized by all nodes
Success: cluster management is resumed
[pgt001] postgres@patroni-1:/postgres/app/postgres/local/dmk/bin> patronictl list
+ Cluster: pgt001 (7346518467491201916) ----------+----+-----------+
| Member | Host | Role | State | TL | Lag in MB |
+----------+----------------+---------+-----------+----+-----------+
| pgt001_1 | 192.168.56.123 | Leader | running | 5 | |
| pgt001_2 | 192.168.56.124 | Replica | streaming | 5 | 0 |
+----------+----------------+---------+-----------+----+-----------+Upgrading etcd in a Patroni cluster is a critical maintenance task that requires careful planning and execution. By following the steps outlined in this guide and leveraging the detailed notes taken during the upgrade process, you can ensure a smooth and successful upgrade while ensuring data integrity. Remember to always test the upgrade process in a staging environment before performing it in production to mitigate any potential risks.
L’article Upgrade etcd in a patroni cluster est apparu en premier sur dbi Blog.
What DEVs need to hear from a DBA and why SQL and RDBMS still matters…
 The Average case
The Average case
As a skilled developer, you are well-versed in the latest trends and fully capable of building an application from scratch. From the frontend to the RESTful API backend, through to the ORM and the database, you have experienced it all.
Having participated in numerous projects and developed substantial code, you have begun to receive feedback from your Sysadmins and users of applications you programmed a few years ago. The application is starting to have performance issues…
-“Simple ! The number of users increased ! The database is now 600GB ! We should provide more resources to the PODs and VMs (my code is good and don’t need rewriting; refactoring was done properly…).”
Makes sense, but the sysadmins tripled the number of CPU and Memory without any benefits whatsoever.
-“Look the database server is too slow the queries are not fast enough !
A DBA should be able to fix that !”
-“We don’t have any, we should call a consultant to make a performance review and help us out of this mess. Customers are still complaining, it is time to invest…”
That’s where a DBA consultant (me) comes along and performs required maintenance and tries to apply standard best practices, tune some parameters here or there and exposes the most intensive queries that need tuning….
Then the DEV Team explains they are using an ORM and can’t “tune Queries” or touch the SQL code because they don’t want to, it would have too many implications on business logic and architecture, and also, they don’t know SQL all that much; it is an old language they used back in their early days as developer.
 1. Why SQL and RDBMS (still)?
1. Why SQL and RDBMS (still)?
As a developer don’t overlook SQL and RDBMS like PostgreSQL. It is still the best way to store and access data when relation between data is important and when that relation can be defined beforehand and is stable (which is usually the case in businesses).
In the following example there are several benefits/reasons for using a RDBMS :
- Data integrity: Enforced by foreign keys and other constraints the table design ensures that the data remains accurate, and consistent, preventing issues like orphaned records.
In this case, an order cannot exist without a customer, and a line item cannot exist without an associated product and order. - Complex Queries: RDBMS are made for JOINs between tables. All the architecture of an RDBMS is helping providing facilities to retrieve and store data efficiently.
- Transaction support: If your requirements are like in this example, an order with multiple steps in it (updating inventory, creating an order record…) must complete successfully together or not at all.
SELECT o.order_id, c.name, p.name, od.quantity, p.price, (od.quantity * p.price) AS total_cost
FROM Orders o
JOIN Customers c ON o.customer_id = c.customer_id
JOIN Order_Details od ON o.order_id = od.order_id
JOIN Products p ON od.product_id = p.product_id
WHERE c.name = 'Bob Kowalski'
ORDER BY o.order_date DESC
LIMIT 100;
NoSQL DB like MongoDB or Cassandra are designed for scalability and flexibility in storing unstructured data, complex joins and transactions are not supported in the same way. They are more suitable if your data structure changes frequently and the application demands high write throughput and horizontal scalability.
In our example an RDBMS like MySQL, MariaDB or PostgreSQL is the best choice to store the “statefullness” of your application but you could use NoSQL DBMS like Redis to cache some data and help not putting too much pressure on the RDBMS by making less calls to it. No one needs to retrieve the same data 50000 times per minute… Use the cache Luke… use the cache…

It would be silly to tell you “Don’t use NoSQL, RDBMS is king !”.
Use them both and understand their limitations.
DEVs love their NoSQL because having a schema-less architecture helps them scale easily and achieve better integration with CI/CD processes, which is traditionally difficult with RDBMS, bonus point for not having to talk to a DBA (which I understand, I talk to myself already enough:)…
In this instance, and perhaps in life overall, one should consider bypassing standardized models and rules established by predecessors only if you comprehend the implications and the original reasons for their existence.
Yes and no. ORMs are one of the good things that happened to Developers and DBAs. It helps creating better code in most of the case and they become quite tunable nowadays.
So please keep your ORM, you need it today since it creates a level of abstraction that is helpful for simple queries and scalable logic and gets you faster and closer to delivery.
The thing is that you have to understand their limitations. And as DBA I am fine with using 100% of ORMs SQL, up until you have a performance issue.
If for some reason your application gets some success and is used enough so that you are being pushed by the business to do better, ask the DBA to provide you the top 10 queries of the last weeks and understand how you can tune those and maybe not use the ORM in some cases.
When the ORM is producing suboptimal queries (queries not performing well enough for business), it might be for several reasons :
- Abstraction: To produce queries, an ORM has to generalize them is such a way that it can cause performance issues. Because the ORM can’t think of all the cases and doesn’t know your data.
- N+1 Problem: Commonly known, this issue is generating more roundtrip calls than it’s advisable to the RDBMS and has been well documented in most documentation since the early 2000s. In general, just think about the data you need and try to understand if you can solve it by creating a query with appropriate JOINs and fetch the required data in one go.
ORMs (Hibernate or Entity for example) allow specifying a batch size for fetching related entities. This means instead of one query per related entity, the ORM will group several entities into fewer queries. Some other ways on the RDBMS side can mitigate those aspects as well like proper indexing, views, materialized views,… - Complex joins: What? an RDBMS can’t handle a lot of JOINs ?! It depends on what you mean by a lot, but generally, RDBMS like SQL Server are having a hard time with more than 6 or 7 JOINs, PostgreSQL you could go a bit further and use GEQO algorithm at the cost of planning time of your execution plan, but overall, an optimizer can’t produce a proper query plan when the cardinality tends towards infinity… which is the case when your ORM queries are generating queries with 86 JOINs !
Note: Understand that it is not just about the number of JOINs. Schema Design indexes and the optimizer capabilities are critical aspects of performance levels, most of the time people are hitting limitations in a RDBMS because they don’t recognize their existence.
If you want to get more info and best practices about ORM I suggest reading this : Hibernate Best Practices (thorben-janssen.com)
4. Performance optimization paths for RDBMS:In addition to what has been said already, you can also optimize your instance to work better.
Earlier, I discussed the limitations on the number of JOINs an optimizer can handle. It’s crucial to recognize that an optimizer’s capabilities are affected by schema design, indexes, and the queries themselves! Like said often by Brent Ozar, you have 3 buttons that you can play with to get better performance : TABLE design, QUERY design and Resources.
People often play with the third one because it is easy to request for more CPU and Memory… cloud providers make you pay for that, it is less the case nowadays though.
So for me you can request additional training for your team, numerous companies offer performance training dedicated for Oracle, SQL Server, PostgreSQL, MariaDB, MySQL,…. and DBI services is one of them.
But you could also first, take leverage of modern monitoring and tools like Query Store on SQL Server or PGANALYZE on PostgreSQL to understand better where your performance bottleneck is.
In most cases, it is easy to query for the top 20 resource-intensive queries, usually in those you will have 3 or 4 that are consuming more resources by 10x. Try to understand why that is and get specialized help if you can’t.
- It is still a matter of using the proper tool for the proper job. Building an architecture based on ORM is a good practice and even if you need to store JSON in the database, I am still up for that ( PostgreSQL supports it in the best way possible ).
- Be prepared that if along the way you need to get more performance at scale, you’ll need to be prepared for a hybrid approach. Using ORM for simple CRUD and raw SQL for the relevant queries. ORM do support writing Native SQL Queries, don’t be afraid to use it.
- In addition use cache capabilities when you can.
- Consult with your Sysadmins and DBAs, they know stuff on your app you want to hear. Trust me on that, they want to help (most of the time:).
Often different teams don’t have the same monitoring tools and don’t look at the same metrics. It is important to understand why. - Be sure to update your knowledge. Often enough I still see DEVs that still are having hard time understanding key concepts or evolution of the best practices… (stored procedures, anti or semi-joins, ….etc).
I do understand that most DEVs are not building a new app every morning from scratch most of them inherit code and logic from old applications build some time ago, architectural decisions are not so often in their hands. Even then, I think we are at a cornerstone of IT evolution, and the next years will be filled with opportunities and new tech, but for the past years most of the projects I have seen failed performance wise, were due to miss communication and over simplifications of complex systems. Platform engineering should solve that and put away the overhead of managing all systems without knowing them all…
L’article What DEVs need to hear from a DBA and why SQL and RDBMS still matters… est apparu en premier sur dbi Blog.
Alfresco – Mass removal/cleanup of documents
At a customer, I recently had a case where a mass-import job was executed on an interface that, in the background, uses Alfresco for document and metadata storage. From the point of view of the interface team, there was no problem as documents were properly being created in Alfresco (although performance wasn’t exceptional). However, after some time, our monitoring started sending us alerts that Solr indexing nearly stopped / was very slow. I might talk about the Solr part in a future blog but what happened is that the interface was configured to import documents into Alfresco in a way that caused too many documents in a single folder.
Too many documents in the same folder of AlfrescoThe interface was trying to import documents in the folder “YYYY/MM/DD/HH” (YYYY being the year, MM the month, DD the day and HH the hour). This might be fine for Business-As-Usual (BAU), when the load isn’t too high, but when mass-importing documents, that meant several thousand documents per folder (5’000, 10’000, 20’000, …), the limit being what Alfresco can ingest in an hour or what the interface manages to send. As you probably know, Alfresco definitively doesn’t like folders with much more than a thousand nodes inside (in particular because of associations and indexing design)… When I saw that, I asked the interface team to stop the import job, but unfortunately, it wasn’t stopped right away and almost 190 000 documents were already imported into Alfresco.
Alfresco APIs for the win?You cannot really let Alfresco in this state since Solr would heavily be impacted by this kind of situation and any change to a document in such folder could result in heavy load. Therefore, from my point of view, the best is to remove the documents and execute a new/correct import with a better distribution of documents per folder.
A first solution could be to restore the DB to a point in time before the activity started, but that means a downtime and anything else that happened in the meantime would be lost. A second option would be to find all the documents imported and remove them through API. As you might know, Share UI will not really be useful in this case since Share will either crash or just take way too long to open the folder, so don’t even try… And even if it is able to somehow open the folder containing XX’XXX nodes, you probably shouldn’t try to delete it because it will take forever, and you will not be able to know what’s the status of this process that runs in the background. Therefore, from my point of view, the only reasonable solution is through API.
Finding documents to deleteAs mentioned, Solr indexing was nearly dead, so I couldn’t rely on it to find what was imported recently. Using REST-API could be possible but there are some limitations when working with huge set of results. In this case, I decided to go with a simple DB query (if you are interested in useful Alfresco DB queries), listing all documents created since the start of the mass-import by the interface user:
SQL> SELECT n.id AS "Node ID",
n.store_id AS "Store ID",
n.uuid AS "Document ID (UUID)",
n.audit_creator AS "Creator",
n.audit_created AS "Creation Date",
n.audit_modifier AS "Modifier",
n.audit_modified AS "Modification Date",
n.type_qname_id
FROM alfresco.alf_node n,
alfresco.alf_node_properties p
WHERE n.id=p.node_id
AND p.qname_id=(SELECT id FROM alf_qname WHERE local_name='content')
AND n.audit_created>='2023-11-23T19:00:00Z'
AND n.audit_creator='itf_user'
AND n.audit_created is not null;
In case the interface isn’t using a dedicated user for the mass-import process, it might be a bit more difficult to find the correct list of documents to be removed, as you would need to take care not to remove the BAU documents… Maybe using a recursive query based on the folder on which the documents were imported or some custom type/metadata or similar. The result of the above query was put in a text file for the processing:
alfresco@acs01:~$ cat alfresco_documents.txt
Node ID Store ID Document ID (UUID) Creator Creation Date Modifier Modification Date TYPE_QNAME_ID
--------- -------- ------------------------------------ --------- ------------------------- --------- ------------------------- -------------
156491155 6 0f16ef7a-4cf1-4304-b578-71480570c070 itf_user 2023-11-23T19:01:02.511Z itf_user 2023-11-23T19:01:03.128Z 265
156491158 4 2f65420a-1105-4306-9733-210501ae7efb itf_user 2023-11-23T19:01:03.198Z itf_user 2023-11-23T19:01:03.198Z 265
156491164 6 a208d56f-df1a-4f2f-bc73-6ab39214b824 itf_user 2023-11-23T19:01:03.795Z itf_user 2023-11-23T19:01:03.795Z 265
156491166 4 908d385f-d6bb-4b94-ba5c-6d6942bb75c3 itf_user 2023-11-23T19:01:03.918Z itf_user 2023-11-23T19:01:03.918Z 265
...
159472069 6 cabf7343-35c4-4e8b-8a36-0fa0805b367f itf_user 2023-11-24T07:50:20.355Z itf_user 2023-11-24T07:50:20.355Z 265
159472079 4 1bcc7301-97ab-4ddd-9561-0ecab8d09efb itf_user 2023-11-24T07:50:20.522Z itf_user 2023-11-24T07:50:20.522Z 265
159472098 6 19d1869c-83d9-449a-8417-b460ccec1d60 itf_user 2023-11-24T07:50:20.929Z itf_user 2023-11-24T07:50:20.929Z 265
159472107 4 bcd0f8a2-68b3-4cc9-b0bd-2af24dc4ff43 itf_user 2023-11-24T07:50:21.074Z itf_user 2023-11-24T07:50:21.074Z 265
159472121 6 74bbe0c3-2437-4d16-bfbc-97bfa5a8d4e0 itf_user 2023-11-24T07:50:21.365Z itf_user 2023-11-24T07:50:21.365Z 265
159472130 4 f984679f-378b-4540-853c-c36f13472fac itf_user 2023-11-24T07:50:21.511Z itf_user 2023-11-24T07:50:21.511Z 265
159472144 6 579a2609-f5be-47e4-89c8-daaa983a314e itf_user 2023-11-24T07:50:21.788Z itf_user 2023-11-24T07:50:21.788Z 265
159472153 4 7f408815-79e1-462a-aa07-182ee38340a3 itf_user 2023-11-24T07:50:21.941Z itf_user 2023-11-24T07:50:21.941Z 265
379100 rows selected.
alfresco@acs01:~$
The above Store ID of ‘6’ is for the ‘workspace://SpacesStore‘ (live document store) and ‘4’ is for the ‘workspace://version2Store‘ (version store):
SQL> SELECT id, protocol, identifier FROM alf_store;
ID PROTOCOL IDENTIFIER
--- ---------- ----------
1 user alfrescoUserStore
2 system system
3 workspace lightWeightVersionStore
4 workspace version2Store
5 archive SpacesStore
6 workspace SpacesStore
Looking at the number of rows for each Store ID gives the exact same number and confirms there are no deleted documents yet:
alfresco@acs01:~$ grep " 4 " alfresco_documents.txt | wc -l
189550
alfresco@acs01:~$
alfresco@acs01:~$ grep " 5 " alfresco_documents.txt | wc -l
0
alfresco@acs01:~$
alfresco@acs01:~$ grep " 6 " alfresco_documents.txt | wc -l
189550
alfresco@acs01:~$
Therefore, there is around 190k docs to remove in total, which is roughly the same number seen in the filesystem. The Alfresco ContentStore has a little bit more obviously since it also contains the BAU documents.
REST-API environment preparationNow that the list is complete, the next step is to extract the IDs of the documents, so that we can use these in REST-API calls. The IDs are simply the third column from the file (Document ID (UUID)):
alfresco@acs01:~$ grep " 6 " alfresco_documents.txt | awk '{print $3}' > input_file_6_id.txt
alfresco@acs01:~$
alfresco@acs01:~$ wc -l alfresco_documents.txt input_file_6_id.txt
379104 alfresco_documents.txt
189550 input_file_6_id.txt
568654 total
alfresco@acs01:~$
Now, to be able to execute REST-API calls, we will also need to define the username/password as well as the URL to be used. I executed the REST-API calls from the Alfresco server itself, so I didn’t really need to think too much about security, and I just used a BASIC authorization method using localhost and HTTPS. If you are executing that remotely, you might want to use tickets instead (and obviously keep the HTTPS protocol). To prepare for the removal, I defined the needed environment variables as follow:
alfresco@acs01:~$ alf_user=admin
alfresco@acs01:~$ read -s -p "Enter ${alf_user} password: " alf_passwd
Enter admin password:
alfresco@acs01:~$
alfresco@acs01:~$ auth=$(echo -n "${alf_user}:${alf_passwd}" | base64)
alfresco@acs01:~$
alfresco@acs01:~$ alf_base_url="https://localhost:8443/alfresco"
alfresco@acs01:~$ alf_node_url="${alf_base_url}/api/-default-/public/alfresco/versions/1/nodes"
alfresco@acs01:~$
alfresco@acs01:~$ input_file="$HOME/input_file_6_id.txt"
alfresco@acs01:~$ output_file="$HOME/output_file_6.txt"
alfresco@acs01:~$
With the above, we have our authorization string (base64 encoding of ‘username:password‘) as well as the Alfresco API URL. In case you wonder, you can find the definition of the REST-APIs in the Alfresco API Explorer. I also defined the input file, which contains all document IDs and an output file, which will contain the list of all documents processed, with the outcome of the command, to be able to check for any issues and follow the progress.
Deleting documents with REST-APIThe last step is now to create a small command/script that will execute the deletion of the documents in REST-API. Things to note here is that I’m using ‘permanent=true‘ so that the documents will not end-up in the trashcan but will be completely and permanently deleted. Therefore, you need to make sure the list of documents is correct! You can obviously set that parameter to false if you really want to, but please be aware that it will impact the performance quite a bit… Otherwise the command is fairly simple, it loops on the input file, execute the deletion query, get its output and log it:
alfresco@acs01:~$ while read -u 3 line; do
out=$(curl -k -s -X DELETE "${alf_node_url}/${line}?permanent=true" -H "accept: application/json" -H "Authorization: Basic ${auth}" | sed 's/.*\(statusCode":[0-9]*\),.*/\1/')
echo "${line} -- ${out}" >> "${output_file}"
done 3< "${input_file}"
The above is the simplest way/form of removal, with a single thread executed on a single server. You can obviously do multi-threaded deletions by splitting the input file into several and triggering commands in parallel, either on the same host or even on other hosts (if you have an Alfresco Cluster). In this example, I was able to get a consistent throughput of ~3130 documents deleted every 5 minutes, which means ~10.4 documents deleted per second. Again, that was on a single server with a single thread:
alfresco@acs01:~$ while true; do
echo "$(date) -- $(wc -l output_file_6.txt)"
sleep 300
done
Fri Nov 24 09:57:38 CET 2023 -- 810 output_file_6.txt
...
Fri Nov 24 10:26:55 CET 2023 -- 18920 output_file_6.txt
Fri Nov 24 10:31:55 CET 2023 -- 22042 output_file_6.txt
Fri Nov 24 10:36:55 CET 2023 -- 25180 output_file_6.txt
Fri Nov 24 10:41:55 CET 2023 -- 28290 output_file_6.txt
...
Since the cURL output (‘statusCode‘) is also recorded in the log file, I was able to confirm that 100% of the queries were successfully executed and all my documents were permanently deleted. With multi-threading and offloading to other members of the Cluster, it would have been possible to increase that by a lot (x5? x10? x20?) but that wasn’t needed in this case since the interface job needed to be updated before a new import could be triggered.
L’article Alfresco – Mass removal/cleanup of documents est apparu en premier sur dbi Blog.
Add authentication in a Feathers.js REST API
Following on from my previous articles: Create REST API from your database in minute with Feathers.js, and Add a UI to explore the Feathers.js API, today I want to add authentication in my Feathers.js REST API. Creation, update and delete operations will be authenticated, while read will remain public.
First step: add authentication to my applicationI’m using the code from my previous articles, and I add the authentication to my Feathers.js API. I use the CLI, it’s quick and easy:
npx feathers generate authenticationI want a simple user + password authentication. To achieve this, I’ve configured my authentication service as follows:
? Which authentication methods do you want to use? Email + Password
? What is your authentication service name? user
? What path should the service be registered on? users
? What database is the service using? SQL
? Which schema definition format do you want to use? TypeBoxNow I have an authentication method available in my application. If you look at the code, a new service users has been generated. It’s used to be retrieved users from the database. I won’t explain here how to create a user, but you can refer to the documentation.
Second step: authenticate the serviceAdditionally, I’m now going to define which method is authenticated in my service. To do this, I open the workshop.ts file. The important part of the code for this configuration is this:
// Initialize hooks
app.service(workshopPath).hooks({
around: {
all: [
schemaHooks.resolveExternal(workshopExternalResolver),
schemaHooks.resolveResult(workshopResolver)
]
},
before: {
all: [
schemaHooks.validateQuery(workshopQueryValidator),
schemaHooks.resolveQuery(workshopQueryResolver)
],
find: [],
get: [],
create: [
schemaHooks.validateData(workshopDataValidator),
schemaHooks.resolveData(workshopDataResolver)
],
patch: [
schemaHooks.validateData(workshopPatchValidator),
schemaHooks.resolveData(workshopPatchResolver)
],
remove: []
},
after: {
all: []
},
error: {
all: []
}
})I add the “authenticate(‘jwt’)” function in create, patch and remove into the before block. This function check the credentials before the call of the main function.
before: {
...
create: [
schemaHooks.validateData(workshopDataValidator),
schemaHooks.resolveData(workshopDataResolver),
authenticate('jwt')
],
patch: [
schemaHooks.validateData(workshopPatchValidator),
schemaHooks.resolveData(workshopPatchResolver),
authenticate('jwt')
],
remove: [authenticate('jwt')]
},The basic authentication (user + password from the db) is managed by Feathers.js, which generates a JWT token on login.
Verify service authenticationFinally, I test the authentication of my service. To do this, I use the Swagger interface configured earlier. The POST method for creating a new record is now authenticated:
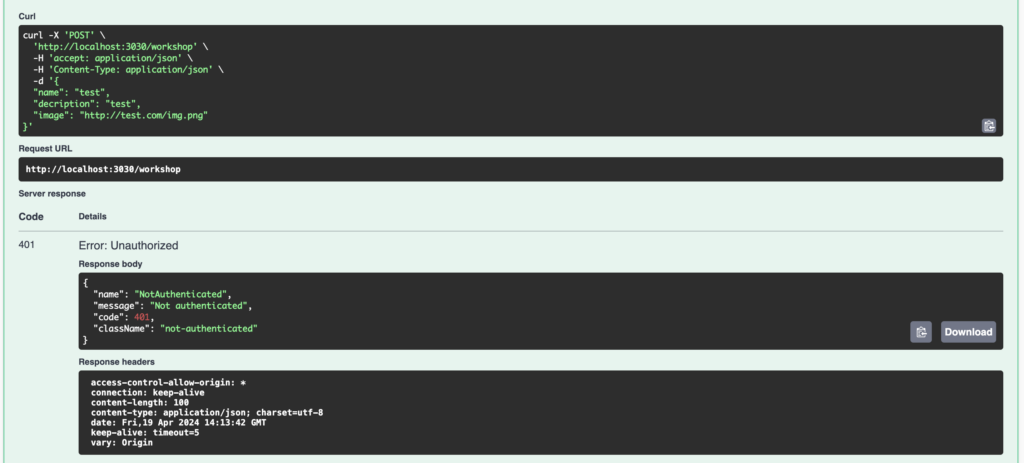
Authentication works correctly, but as I don’t pass a JWT token, I get the error 401 Unauthorized.
ConclusionAdding authentication to a Feathers.js REST API is as easy as generating the service itself.
Feathers.js offers different authentication strategies, such as Local (user + password), JWT or oAuth. But if that’s not enough, you can also create a custom strategy.
In a future article, I’ll explain how to adapt the Swagger interface to manage authentication.
L’article Add authentication in a Feathers.js REST API est apparu en premier sur dbi Blog.
Detect XZ Utils CVE 2024-3094 with Tetragon
The recent discovery of the XZ Utils backdoor, classified as CVE 2024-3094, has been now well documented. Detecting it with Tetragon from Isovalent (now part of Cisco) has been explained in this blog post. I also did some research and experimented with this vulnerability. I wondered how we could leverage Tetragon capabilities to detect it before it was known. There are other vulnerabilities out there, so we need to be prepared for the unknown. For this we have to apply a security strategy called Zero Trust. I wrote another blog post on this topic with another example and another tool if you want to have a look. Let’s build an environment on which we can experiment and learn more about it. Follow along!
 Setup an environment for CVE 2024-3094
Setup an environment for CVE 2024-3094
We have learned that this vulnerability needs an x86 architecture to be exploited and that it targets several Linux distribution (source here). I’ve used an Ubuntu 22.04 virtual machine in Azure to setup the environment. To exploit this vulnerability, we’re going to use the GitHub resource here.
This vulnerability is related to the library liblzma.so used by the ssh daemon so let’s switch to the root user and install openssh-server along with other packages we will use later:
azureuser@Ubuntu22:~$ sudo -i
root@Ubuntu22:~# apt-get update && apt-get install -y golang-go curl openssh-server net-tools python3-pip wget vim git file bsdmainutils jq
Let’s use ssh key authentication (as this is how the vulnerable library can be exploited), start the ssh daemon and see which version of the library it uses:
root@Ubuntu22:~# which sshd
/usr/sbin/sshd
root@Ubuntu22:~# sed -E -i 's/^#?PasswordAuthentication .*/PasswordAuthentication no/' /etc/ssh/sshd_config
root@Ubuntu22:~# service ssh status
* sshd is not running
root@Ubuntu22:~# service ssh start
* Starting OpenBSD Secure Shell server sshd
root@Ubuntu22:~# service ssh status
* sshd is running
root@Ubuntu22:~# ldd /usr/sbin/sshd|grep liblzma
liblzma.so.5 => /lib/x86_64-linux-gnu/liblzma.so.5 (0x00007ae3aac37000)
root@Ubuntu22:~# file /lib/x86_64-linux-gnu/liblzma.so.5
/lib/x86_64-linux-gnu/liblzma.so.5: symbolic link to liblzma.so.5.2.5
Here it uses version 5.2.5, sometimes it uses version 5.4.5 from the tests I did on other distributions. The vulnerable versions are 5.6.0 and 5.6.1. So by default our machine is not vulnerable. To make it so, we need to upgrade this library to one of these vulnerable versions as shown below:
root@Ubuntu22:~# wget https://snapshot.debian.org/archive/debian/20240328T025657Z/pool/main/x/xz-utils/liblzma5_5.6.1-1_amd64.deb
root@Ubuntu22:~# apt-get install --allow-downgrades --yes ./liblzma5_5.6.1-1_amd64.deb
root@Ubuntu22:~# file /lib/x86_64-linux-gnu/liblzma.so.5
/lib/x86_64-linux-gnu/liblzma.so.5: symbolic link to liblzma.so.5.6.1
We are now using the vulnerable library in version 5.6.1. Next we can use the files and xzbot tool from the GitHub project as shown below:
root@Ubuntu22:~# git clone https://github.com/amlweems/xzbot.git
root@Ubuntu22:~# cd xzbot/
To be able to exploit this vulnerability we can’t just use the vulnerable library. In fact the backdoor uses a hardcoded ED448 public key for signature and we don’t have the associated private key. To be able to trigger that backdoor, the author of the tool xzbot replaced them with their own key pair they’ve generated. We then need to replace the vulnerable library with the patched one using these keys as follows:
root@Ubuntu22:~# cp ./assets/liblzma.so.5.6.1.patch /lib/x86_64-linux-gnu/liblzma.so.5.6.1
Now everything is ready to exploit this vulnerability with the xzbot tool. We just need to compile it with the go package we installed at the beginning:
root@Ubuntu22:~# go build
root@Ubuntu22:~# ./xzbot -h
Usage of ./xzbot:
-addr string
ssh server address (default "127.0.0.1:2222")
-cmd string
command to run via system() (default "id > /tmp/.xz")
-seed string
ed448 seed, must match xz backdoor key (default "0")
Let’s see now how we could use Tetragon to detect something by applying a Zero Trust strategy. At this stage we consider we don’t know anything about this vulnerability and we are using Tetragon as a security tool for our environment. Here we don’t use Kubernetes, we just have a Ubuntu 22.04 host but we can still use Tetragon by running it into a docker container.
We install docker in our machine by following the instructions described here:
root@Ubuntu22:~# sudo apt-get install ca-certificates curl
root@Ubuntu22:~# sudo install -m 0755 -d /etc/apt/keyrings
root@Ubuntu22:~# sudo curl -fsSL https://download.docker.com/linux/ubuntu/gpg -o /etc/apt/keyrings/docker.asc
root@Ubuntu22:~# sudo chmod a+r /etc/apt/keyrings/docker.asc
root@Ubuntu22:~# echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.asc] https://download.docker.com/linux/ubuntu \
$(. /etc/os-release && echo "$VERSION_CODENAME") stable" | \
sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
root@Ubuntu22:~# sudo apt-get update
root@Ubuntu22:~# sudo apt-get install docker-ce docker-ce-cli containerd.io docker-buildx-plugin docker-compose-plugin
Then we install Tetragon in a docker container by following the instructions here:
root@Ubuntu22:~# docker run --name tetragon --rm -d \
--pid=host --cgroupns=host --privileged \
-v /sys/kernel:/sys/kernel \
quay.io/cilium/tetragon:v1.0.3 \
/usr/bin/tetragon --export-filename /var/log/tetragon/tetragon.log
Now everything is ready and we can trigger the backdoor and see what Tetragon can observe. We open a new shell by using the azureuser. We jump into the Tetragon container and monitor the log file for anything related to ssh as shown below:
azureuser@Ubuntu22:~$ sudo docker exec -it 76dc8c268caa bash
76dc8c268caa:/# tail -f /var/log/tetragon/tetragon.log | grep ssh
In another shell (the one with the root user), we can start the exploit by using the xzbot tool. We execute the command sleep 60 so we can observe in real time what is happening:
root@Ubuntu22:~/xzbot# ./xzbot -addr 127.0.0.1:22 -cmd "sleep 60"
This is an example of a malicious actor connecting through the backdoor to get a shell on our compromised Ubuntu machine. Below is what we can see in our Tetragon shell (the output has been copied and pasted for being parsed with jq to provide a better reading and we’ve kept only the process execution event):
{
"process_exec": {
"process": {
"exec_id": "OjIwNjAyNjc1NDE0MTU2OjE1NDY0MA==",
"pid": 154640,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"arguments": "-D -R",
"flags": "execve rootcwd clone",
"start_time": "2024-04-23T12:03:08.447280556Z",
"auid": 4294967295,
"parent_exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"tid": 154640
},
"parent": {
"exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"pid": 742,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"flags": "procFS auid rootcwd",
"start_time": "2024-04-23T06:19:59.931865800Z",
"auid": 4294967295,
"parent_exec_id": "OjM4MDAwMDAwMDox",
"tid": 742
}
},
"time": "2024-04-23T12:03:08.447279856Z"
}
...
{
"process_exec": {
"process": {
"exec_id": "OjIwNjAyOTk4NzY3ODU0OjE1NDY0Mg==",
"pid": 154642,
"uid": 0,
"cwd": "/",
"binary": "/bin/sh",
"arguments": "-c \"sleep 60\"",
"flags": "execve rootcwd clone",
"start_time": "2024-04-23T12:03:08.770634054Z",
"auid": 4294967295,
"parent_exec_id": "OjIwNjAyNjc1NDE0MTU2OjE1NDY0MA==",
"tid": 154642
},
"parent": {
"exec_id": "OjIwNjAyNjc1NDE0MTU2OjE1NDY0MA==",
"pid": 154640,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"arguments": "-D -R",
"flags": "execve rootcwd clone",
"start_time": "2024-04-23T12:03:08.447280556Z",
"auid": 4294967295,
"parent_exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"tid": 154640
}
},
"time": "2024-04-23T12:03:08.770633854Z"
}
Here we have all the interesting information about the process as well as the link to its parent process. With Tetragon Entreprise we could have a graphical view of these linked processes. As we are using the Community Edition, we can use the ps command instead here to get a more graphical view as shown below:
azureuser@Ubuntu22:~$ ps -ef --forest
root 742 1 0 06:19 ? 00:00:00 sshd: /usr/sbin/sshd -D [listener] 1 of 10-100 startups
root 154640 742 2 12:03 ? 00:00:00 \_ sshd: root [priv]
sshd 154641 154640 0 12:03 ? 00:00:00 \_ sshd: root [net]
root 154642 154640 0 12:03 ? 00:00:00 \_ sh -c sleep 60
root 154643 154642 0 12:03 ? 00:00:00 \_ sleep 60
The 2 processes highlighted above are those related to the Tetragon output. Let’s now see what Tetragon displays in case of a normal ssh connection.
Tetragon – Normal ssh connectionWe first need to setup a pair of keys for the root user (to better compare it with the output above):
root@Ubuntu22:~# ssh-keygen
root@Ubuntu22:~# cat ~/.ssh/id_rsa.pub > ~/.ssh/authorized_keys
root@Ubuntu22:~# ssh root@127.0.0.1
Welcome to Ubuntu 22.04.4 LTS (GNU/Linux 6.5.0-1017-azure x86_64)
For the key generation we use the default folder with no passphase. We see we can connect with the root user to the localhost by using the generated keys. We can then use the same method as above to launch Tetragon and the ps command to capture this ssh connection. Here is what we can see with Tetragon:
{
"process_exec": {
"process": {
"exec_id": "OjU1ODY3OTQ0NTI0ODY6NDc1MDE=",
"pid": 47501,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"arguments": "-D -R",
"flags": "execve rootcwd clone",
"start_time": "2024-04-23T07:52:52.566318686Z",
"auid": 4294967295,
"parent_exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"tid": 47501
},
"parent": {
"exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"pid": 742,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"flags": "procFS auid rootcwd",
"start_time": "2024-04-23T06:19:59.931865800Z",
"auid": 4294967295,
"parent_exec_id": "OjM4MDAwMDAwMDox",
"tid": 742
}
},
"time": "2024-04-23T07:52:52.566318386Z"
}
{
"process_exec": {
"process": {
"exec_id": "OjU1ODgxMzk5MjM5NjA6NDc2MDQ=",
"pid": 47604,
"uid": 0,
"cwd": "/root",
"binary": "/bin/bash",
"flags": "execve clone",
"start_time": "2024-04-23T07:52:53.911790360Z",
"auid": 0,
"parent_exec_id": "OjU1ODY3OTQ0NTI0ODY6NDc1MDE=",
"tid": 47604
},
"parent": {
"exec_id": "OjU1ODY3OTQ0NTI0ODY6NDc1MDE=",
"pid": 47501,
"uid": 0,
"cwd": "/",
"binary": "/usr/sbin/sshd",
"arguments": "-D -R",
"flags": "execve rootcwd clone",
"start_time": "2024-04-23T07:52:52.566318686Z",
"auid": 4294967295,
"parent_exec_id": "OjE0MTYwMDAwMDAwOjc0Mg==",
"tid": 47501
}
},
"time": "2024-04-23T07:52:53.911789660Z"
}
And the output of the corresponding ps command:
azureuser@Ubuntu22:~$ ps -ef --forest
root 742 1 0 06:19 ? 00:00:00 sshd: /usr/sbin/sshd -D [listener] 0 of 10-100 startups
root 45501 742 10 07:49 ? 00:00:00 \_ sshd: root@pts/1
root 47604 45501 0 07:49 pts/1 00:00:00 \_ -bash
You can see there is a difference but it is not easy to spot! In the normal connection it launches a bash under sshd and through the backdoor it is running a command with sh instead.
Wrap upWe have seen how we can leverage Tetragon to observe anything happening on this machine. Even for unknown threats, you get some information but you have to know first how your system is working in very details. You need to have a baseline for each running process on your machine to be able to detect any deviation. That is what we call the Zero Trust strategy and it is the only way to detect such stealthy backdoor.
It may seem tenuous and it is, however that is how Andres Freund discovered it when he noticed ssh was several milliseconds slower than it should. The famous adage says that the devil is in the detail, this backdoor discovery proves that this is especially true when it comes to security.
L’article Detect XZ Utils CVE 2024-3094 with Tetragon est apparu en premier sur dbi Blog.
A first look at openSUSE Leap Micro 6.0
Recently the openSUSE project announced the Alpha release of Leap Micro 6.0. This version of the openSUSE operating system is optimized for container workloads and edge computing. One of the cool features of this version of the OS is, that the root file system is read only. Updates to the operating system are atomic / transactional, which means the Btrfs snapshots are used when the system is patched. When it goes wrong, you can just boot from an old snapshot and you’re done. You can also not damage the root file system by mistake, as it is read only.
When you check the available installation media, you’ll notice that there is no version with an installer. Either you need to go for a pre-configured image ( raw or qcow ) or you go for the self install image. We’ll go for the latter for the scope of this post.
Booting from self install image almost directly brings you to this screen:
You should be aware of what you’re doing here, obviously all data will be destroyed if you continue. The self install image will use the whole disk and auto-expand to the maximum size:
What follows after, is a really minimal configuration of the system (keyboard, time zone, …):
Once you’re through that the system will reboot, perform some initial configuration and you’re ready to use it:
If you have DHCP, then the system should have got an IP address automatically (otherwise you need to configure the image with Combustion):
Usually I am not using any graphical tools to work on a Linux server, but as it is mentioned after login, let’s enable cockpit:

Once it is running, the Cockpit interface is available at https://[IP-ADDRESS]:9090 and you can use the root account to log in:
By default you’ll not be able to login to the system with the root account over ssh:
dwe@ltdwe:~$ ssh root@192.168.122.161
(root@192.168.122.161) Password:
(root@192.168.122.161) Password:
(root@192.168.122.161) Password:
We can use the “Terminal” in Cockpit to fix this (shouldn’t be done in production, of course):
One of the first things I usually do is to update the system. Instead of using zypper you need to use “transaction-update” on Leap Micro (remember the root file system is read only, so zypper will not work, even if transactional-update uses zypper in the background):
localhost:~ $ transactional-update up
Checking for newer version.
Repository 'repo-main (6.0)' is invalid.
[openSUSE:repo-main|http://cdn.opensuse.org/distribution/leap-micro/6.0/product/repo/Leap-Micro-6.0-x86_64-Media1] Valid metadata not found at specified URL
History:
- Signature verification failed for repomd.xml
- Can't provide /repodata/repomd.xml
Please check if the URIs defined for this repository are pointing to a valid repository.
Some of the repositories have not been refreshed because of an error.
transactional-update 4.6.5 started
Options: up
Separate /var detected.
2024-04-23 13:30:37 tukit 4.6.5 started
2024-04-23 13:30:37 Options: -c2 open
2024-04-23 13:30:37 Using snapshot 2 as base for new snapshot 3.
2024-04-23 13:30:37 /var/lib/overlay/2/etc
2024-04-23 13:30:37 Syncing /etc of previous snapshot 1 as base into new snapshot "/.snapshots/3/snapshot"
2024-04-23 13:30:37 SELinux is enabled.
ID: 3
2024-04-23 13:30:38 Transaction completed.
Calling zypper up
zypper: nothing to update
Removing snapshot #3...
2024-04-23 13:30:40 tukit 4.6.5 started
2024-04-23 13:30:40 Options: abort 3
2024-04-23 13:30:41 Discarding snapshot 3.
2024-04-23 13:30:41 Transaction completed.
transactional-update finished
This fails because the key of the repository changed. Usually you would fix this with “zypper refresh” but this fails as well as the file system is read only:
localhost:~ $ zypper refresh
New repository or package signing key received:
Repository: repo-main (6.0)
Key Fingerprint: AD48 5664 E901 B867 051A B15F 35A2 F86E 29B7 00A4
Key Name: openSUSE Project Signing Key <opensuse@opensuse.org>
Key Algorithm: RSA 4096
Key Created: Mon Jun 20 16:03:14 2022
Key Expires: Fri Jun 19 16:03:14 2026
Rpm Name: gpg-pubkey-29b700a4-62b07e22
Note: Signing data enables the recipient to verify that no modifications occurred after the data
were signed. Accepting data with no, wrong or unknown signature can lead to a corrupted system
and in extreme cases even to a system compromise.
Note: A GPG pubkey is clearly identified by its fingerprint. Do not rely on the key's name. If
you are not sure whether the presented key is authentic, ask the repository provider or check
their web site. Many providers maintain a web page showing the fingerprints of the GPG keys they
are using.
Do you want to reject the key, trust temporarily, or trust always? [r/t/a/?] (r): y
: Invalid answer 'y'.
[r/t/a/?] (r): a
Subprocess failed. Error: Failed to import public key [35A2F86E29B700A4-62b07e22] [openSUSE Project Signing Key <opensuse@opensuse.org>] [expires: 2026-06-19]
History:
- Command exited with status 1.
- error: /var/tmp/zypp.Ta065o/pubkey-35A2F86E29B700A4-S17NWa: key 1 import failed.
- error: can't create transaction lock on /usr/lib/sysimage/rpm/.rpm.lock (Read-only file system)
The way to do it is, once more, using “transactional-update”:
localhost:~ $ transactional-update run zypper refresh
Checking for newer version.
transactional-update 4.6.5 started
Options: run zypper refresh
Separate /var detected.
2024-04-23 14:38:21 tukit 4.6.5 started
2024-04-23 14:38:21 Options: -c2 open
2024-04-23 14:38:21 Using snapshot 2 as base for new snapshot 3.
2024-04-23 14:38:21 /var/lib/overlay/2/etc
2024-04-23 14:38:21 Syncing /etc of previous snapshot 1 as base into new snapshot "/.snapshots/3/snapshot"
2024-04-23 14:38:21 SELinux is enabled.
ID: 3
2024-04-23 14:38:22 Transaction completed.
2024-04-23 14:38:22 tukit 4.6.5 started
2024-04-23 14:38:22 Options: call 3 zypper refresh
2024-04-23 14:38:22 Executing `zypper refresh`:
Repository 'repo-main (6.0)' is up to date.
All repositories have been refreshed.
2024-04-23 14:38:22 Application returned with exit status 0.
2024-04-23 14:38:22 Transaction completed.
2024-04-23 14:38:22 tukit 4.6.5 started
2024-04-23 14:38:22 Options: close 3
Relabeled /var/lib/YaST2 from unconfined_u:object_r:var_lib_t:s0 to unconfined_u:object_r:rpm_var_lib_t:s0
Relabeled /var/lib/YaST2/cookies from unconfined_u:object_r:var_lib_t:s0 to unconfined_u:object_r:rpm_var_lib_t:s0
2024-04-23 14:38:23 New default snapshot is #3 (/.snapshots/3/snapshot).
2024-04-23 14:38:23 Transaction completed.
Please reboot your machine to activate the changes and avoid data loss.
New default snapshot is #3 (/.snapshots/3/snapshot).
transactional-update finished
Now we’re ready to go. Podman is installed by default:
localhost:~ $ podman --version
podman version 4.9.3
… so you can start to deploy your containers.
L’article A first look at openSUSE Leap Micro 6.0 est apparu en premier sur dbi Blog.
Another file system for Linux: bcachefs (3) – Mirroring/Replicas
This is the third post in this little series about bcachefs. The first post was all about the basics while the second post introduced bcachefs over multiple devices. What we did not discuss so far is, what bcache has to offer when it comes to mirroring. By default bcachefs stripes your data across all the devices in the file systems. As devices do not need to be of the same size, the one(s) with the most free space will be favored. The goal of this is, that all devices fill up at the same pace. This usually does not protect you from a failure of a device, except you lose a device which does not contain any data.
To address this, bcachefs comes with a concept which is called “replication”. You can think of replication like a RAID 1/10, which means mirroring and striping. Given the list of available devices in the setup we’re currently using we have enough devices to play with this:
tumbleweed:~ $ lsblk | grep -w "4G"
└─vda3 254:3 0 1.4G 0 part [SWAP]
vdb 254:16 0 4G 0 disk
vdc 254:32 0 4G 0 disk
vdd 254:48 0 4G 0 disk
vde 254:64 0 4G 0 disk
vdf 254:80 0 4G 0 disk
vdg 254:96 0 4G 0 disk
Let’s assume we want to have a 4gb file system but we also want to have the data mirrored to another device, just in case we lose one. With bcachefs this can easily be done like this:
tumbleweed:~ $ bcachefs format --force --replicas=2 /dev/vdb /dev/vdc
tumbleweed:~ $ mount -t bcachefs /dev/vdb:/dev/vdc /mnt/dummy/
As data is now mirrored this should result in a file system of around 4gb, instead of 8gb:
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 4.0M 7.2G 1% /mnt/dummy
It does not, so what could be the reason for this? Looking at the usage of the file system we see this:
tumbleweed:~ $ bcachefs fs usage /mnt/dummy/
Filesystem: d8a3d289-bb0f-4df0-b15c-7bb4ada51073
Size: 7902739968
Used: 78118912
Online reserved: 0
Data type Required/total Durability Devices
btree: 1/2 2 [vdb vdc] 4194304
(no label) (device 0): vdb rw
data buckets fragmented
free: 4255907840 16235
sb: 3149824 13 258048
journal: 33554432 128
btree: 2097152 8
user: 0 0
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 0 0
capacity: 4294967296 16384
(no label) (device 1): vdc rw
data buckets fragmented
free: 4255907840 16235
sb: 3149824 13 258048
journal: 33554432 128
btree: 2097152 8
user: 0 0
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 0 0
capacity: 4294967296 16384
As we currently do not have any user data in this file system, let’s write a 100MB file into it and check again how this looks like from a usage perspective:
tumbleweed:~ $ dd if=/dev/zero of=/mnt/dummy/dummy bs=1M count=100
100+0 records in
100+0 records out
104857600 bytes (105 MB, 100 MiB) copied, 0.0294275 s, 3.6 GB/s
tumbleweed:~ $ ls -lha /mnt/dummy/
total 100M
drwxr-xr-x 3 root root 0 Apr 17 17:04 .
dr-xr-xr-x 1 root root 10 Apr 17 10:41 ..
-rw-r--r-- 1 root root 100M Apr 17 17:05 dummy
drwx------ 2 root root 0 Apr 17 16:54 lost+found
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 207M 7.0G 3% /mnt/dummy
So instead of using 100MB on disk, we’re actually using 200MB, so this makes sense again, you just need to be aware of how the numbers are presented and how you come to this disk usage. Anyway, let’s have a look at the disk usage as the “bcachefs” utility reports it once more:
tumbleweed:~ $ bcachefs fs usage /mnt/dummy/
Filesystem: d8a3d289-bb0f-4df0-b15c-7bb4ada51073
Size: 7902739968
Used: 290979840
Online reserved: 0
Data type Required/total Durability Devices
btree: 1/2 2 [vdb vdc] 7340032
user: 1/2 2 [vdb vdc] 209715200
(no label) (device 0): vdb rw
data buckets fragmented
free: 4148953088 15827
sb: 3149824 13 258048
journal: 33554432 128
btree: 3670016 14
user: 104857600 400
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 524288 2
capacity: 4294967296 16384
(no label) (device 1): vdc rw
data buckets fragmented
free: 4148953088 15827
sb: 3149824 13 258048
journal: 33554432 128
btree: 3670016 14
user: 104857600 400
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 524288 2
capacity: 4294967296 16384
This is telling us more or less the same: We have around 100MB of user data on each of the devices, and this 100MB of user data are spread across 400 buckets. A bucket is 512KiB bytes per default, which you can read out of the super block:
tumbleweed:~ $ bcachefs show-super /dev/vdb | grep "Bucket size"
Bucket size: 256 KiB
Bucket size: 256 KiB
If you do the math: 104857600/(512*1024) gives 200 buckets, but as we replicate every bucket we have 400. Same story here, you need to know where this 400 buckets come from to make any sense out of it.
In the next post we’ll look at device labels and targets.
L’article Another file system for Linux: bcachefs (3) – Mirroring/Replicas est apparu en premier sur dbi Blog.
Apache Kafka and ksqlDB
After two introduction blogs on Apache Kafka (ie. Apache Kafka Concepts by Example and Apache Kafka Consumer Group), it is time to discover the wide ecosystem around it. In this blog post, I will play with ksqlDB, streams and tables.
ksqlDBksqlDB is a server that takes benefit of an Apache Kafka infrastructure for real time data streaming. It can be used to capture events (via, for example, Kafka Connect), transform events, expose views (or tables).
Starting ksqlDB server is easy. First, we need to set the bootstrap servers of our Kafka cluster in etc/ksqldb/ksql-server.properties file:
bootstrap.servers=localhost:29092
As it is used for a proof of concept, I use a one broker cluster (ie. without high availability). Of course, ksqlDB server supports HA.
The command to start:
bin/ksql-server-start etc/ksqldb/ksql-server.properties
And once, it up and running, you should see this:
[2024-04-19 11:43:25,485] INFO Waiting until monitored service is ready for metrics collection (io.confluent.support.metrics.BaseMetricsReporter:173)
[2024-04-19 11:43:25,485] INFO Monitored service is now ready (io.confluent.support.metrics.BaseMetricsReporter:185)
[2024-04-19 11:43:25,485] INFO Attempting to collect and submit metrics (io.confluent.support.metrics.BaseMetricsReporter:144)
[2024-04-19 11:43:25,486] INFO ksqlDB API server listening on http://0.0.0.0:8088 (io.confluent.ksql.rest.server.KsqlRestApplication:385)
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
Server 0.29.0 listening on http://0.0.0.0:8088
To access the KSQL CLI, run:
ksql http://0.0.0.0:8088
[2024-04-19 11:43:25,489] INFO Server up and running (io.confluent.ksql.rest.server.KsqlServerMain:153)
[2024-04-19 11:47:04,248] INFO Successfully submitted metrics to Confluent via secure endpoint (io.confluent.support.metrics.submitters.ConfluentSubmitter:146)
Now, we are ready to start the ksqlDB client:
bin/ksql http://localhost:8088
if all went well, you should receive the ksql prompt and see the server status as RUNNING:
===========================================
= _ _ ____ ____ =
= | | _____ __ _| | _ \| __ ) =
= | |/ / __|/ _` | | | | | _ \ =
= | <\__ \ (_| | | |_| | |_) | =
= |_|\_\___/\__, |_|____/|____/ =
= |_| =
= The Database purpose-built =
= for stream processing apps =
===========================================
Copyright 2017-2022 Confluent Inc.
CLI v0.29.0, Server v0.29.0 located at http://localhost:8088
Server Status: RUNNING
Having trouble? Type 'help' (case-insensitive) for a rundown of how things work!
ksql>
One advantage, and a drawback as well, is that a Kafka topic (refer to my previous blog post if you don’t know what this is) can store anything and each message can have its own format (text or binary). Schema Registry can enforce formatting rules, versioning and serialization/de-serialization information (I will cover that in another blog). ksql also enforces the formatting when defining a stream. For example, I create a order stream with 4 fields:
- order id
- customer id
- product id
- status
ksql> create stream order_stream (order_id int, customer_id int, product_id int, status_id int)
with (kafka_topic='order_topic',value_format='json',partitions=1);
Message
----------------
Stream created
----------------
To check what happened in the background, I could either use Kafka UI or even ksql:
ksql> show streams;
Stream Name | Kafka Topic | Key Format | Value Format | Windowed
------------------------------------------------------------------------------------------
KSQL_PROCESSING_LOG | default_ksql_processing_log | KAFKA | JSON | false
ORDER_STREAM | order_topic | KAFKA | JSON | false
------------------------------------------------------------------------------------------
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------
default_ksql_processing_log | 1 | 1
order_topic | 1 | 1
---------------------------------------------------------------
ksql>
We can see our stream and the associated backend topic.
Let’s insert data in the stream:
insert into order_stream (order_id, customer_id, product_id, status_id) values (1, 10, 21, 0);
And check data is there:
ksql> select * from order_stream;
+-----------------------+-----------------------+-----------------------+-----------------------+
|ORDER_ID |CUSTOMER_ID |PRODUCT_ID |STATUS_ID |
+-----------------------+-----------------------+-----------------------+-----------------------+
|1 |10 |21 |0 |
Query Completed
Query terminated
And in the topic, what is actually stored? We can run a kafka-console-consumer.sh to see it. By the way, command must be started before inserting data or with --from-beginning option:
$ ./kafka-console-consumer.sh --bootstrap-server localhost:29092 --topic order_topic
{"ORDER_ID":1,"CUSTOMER_ID":10,"PRODUCT_ID":21,"STATUS_ID":0}
Every update of the order status will imply a new event in the order_stream.
TableLet’s say we want to see the status name instead of the status id which has no meaning to us. It is possible to create a table which will contain both status_id and the associated status_name:
create table status (status_id int primary key, status_name varchar)
with (kafka_topic='status',value_format='json',partitions=1);
As you can see, when defining a table, we have to define a primary key. One of the main difference is when querying a table, only the last value of each primary key will be provided.
Let’s insert some data into status table:
insert into status (status_id, status_name) values (0,'Pending');
insert into status (status_id, status_name) values (1,'Processing');
insert into status (status_id, status_name) values (2,'Shipped');
insert into status (status_id, status_name) values (3,'Delivered');
insert into status (status_id, status_name) values (4,'Canceled');
And we can query it:
ksql> select * from status emit changes;
+-------------------------------------------------+-------------------------------------------------+
|STATUS_ID |STATUS_NAME |
+-------------------------------------------------+-------------------------------------------------+
|0 |Pending |
|1 |Processing |
|2 |Shipped |
|3 |Delivered |
|4 |Canceled |
Oops, I see a typo in Canceled. How to correct it? By inserting a new record with the update:
insert into status (status_id, status_name) values (4,'Cancelled');
If I keep the select open, I will see the update and if I query it again, I see the fixed status_name:
ksql> select * from status emit changes;
+-------------------------------------------------+-------------------------------------------------+
|STATUS_ID |STATUS_NAME |
+-------------------------------------------------+-------------------------------------------------+
|0 |Pending |
|1 |Processing |
|2 |Shipped |
|3 |Delivered |
|4 |Cancelled |
One interest of this is that you can join table and stream like in any SQL database to improve the result. The SQL query to create that stream is:
create stream order_stream_with_status as
select order_id, customer_id, order_stream.status_id, product_id, status.status_name as status_name
from order_stream left join status on order_stream.status_id = status.status_id
emit changes;
Here I create a new stream (ie. order_stream_with_status) based on an stream order_stream and joined to table status_name. “emit changes” is to see all changes (messages) from the topic.
Let’s see what is happening while selecting from this new stream when inserting in order_stream:
select * from ORDER_STREAM_WITH_STATUS emit changes;
+------------------+------------------+------------------+------------------+------------------+
|ORDER_STREAM_STATU|ORDER_ID |CUSTOMER_ID |PRODUCT_ID |STATUS_NAME |
|S_ID | | | | |
+------------------+------------------+------------------+------------------+------------------+
|0 |1 |10 |21 |Pending |
Great! Now, we see a status name. Of course, this can be done with other columns as well. We can even use Kafka Connect to get data from a database like MySQL or Postgres.
Filtered StreamNow, let’s say our shop bills customer when order has been shipped. Obviously, they don’t want to be notified on all events received in order_stream, thus we can create a new stream which will filter on status_id=2. The sql query for that can be:
create stream order_stream_billing as
select order_id, customer_id, order_stream.status_id, product_id, status.status_name as status_name
from order_stream left join status on order_stream.status_id = status.status_id
where order_stream.status_id=2
emit changes;
We can insert few orders into order_stream:
insert into order_stream (order_id, customer_id, product_id, status_id) values (1, 10, 21, 0);
insert into order_stream (order_id, customer_id, product_id, status_id) values (2, 10, 21, 0);
insert into order_stream (order_id, customer_id, product_id, status_id) values (3, 10, 21, 0);
insert into order_stream (order_id, customer_id, product_id, status_id) values (4, 10, 21, 0);
insert into order_stream (order_id, customer_id, product_id, status_id) values (5, 10, 21, 0);
And then update their status:
insert into order_stream (order_id, customer_id, product_id, status_id) values (1, 10, 21, 1);
insert into order_stream (order_id, customer_id, product_id, status_id) values (2, 10, 21, 1);
insert into order_stream (order_id, customer_id, product_id, status_id) values (3, 10, 21, 2);
insert into order_stream (order_id, customer_id, product_id, status_id) values (4, 10, 21, 1);
insert into order_stream (order_id, customer_id, product_id, status_id) values (5, 10, 21, 2);
What will the select show? You guessed right, only two of them will be in the queue:
select * from ORDER_STREAM_billing emit changes;
+------------------+------------------+------------------+------------------+------------------+
|ORDER_STREAM_STATU|ORDER_ID |CUSTOMER_ID |PRODUCT_ID |STATUS_NAME |
|S_ID | | | | |
+------------------+------------------+------------------+------------------+------------------+
|2 |3 |10 |21 |Shipped |
|2 |5 |10 |21 |Shipped |
While doing all these tests, I forgot to check what was happening on the pure Kafka side. Let’s see:
ksql> show topics;
Kafka Topic | Partitions | Partition Replicas
---------------------------------------------------------------
ORDER_STREAM_BILLING | 1 | 1
ORDER_STREAM_WITH_STATUS | 1 | 1
default_ksql_processing_log | 1 | 1
order_topic | 1 | 1
status | 1 | 1
---------------------------------------------------------------
The two streams with upper case were created like that because topic name was not specified during the creation and, as per documentation, the upper case of table name is used as topic name.
In short, ksqlDB is part of an Extract, Transform and Load (ETL) process.
L’article Apache Kafka and ksqlDB est apparu en premier sur dbi Blog.
Another file system for Linux: bcachefs (2) – multi device file systems
In the last post, we’ve looked at the very basics when it comes to bcachefs, a new file system which was added to the Linux kernel starting from version 6.7. While we’ve already seen how easy it is to create a new file system using a single device, encrypt and/or compress it and that check summing of meta data and user data is enabled by default, there is much more you can do with bcachefs. In this post we’ll look at how you can work with a file system that spans multiple devices, which is quite common in today’s infrastructures.
When we looked at the devices available to the system in the last post, it looked like this:
tumbleweed:~ $ lsblk | grep -w "4G"
└─vda3 254:3 0 1.4G 0 part [SWAP]
vdb 254:16 0 4G 0 disk
vdc 254:32 0 4G 0 disk
vdd 254:48 0 4G 0 disk
vde 254:64 0 4G 0 disk
vdf 254:80 0 4G 0 disk
vdg 254:96 0 4G 0 disk
This means we have six unused block devices to play with. Lets start again with the most simple case, one device, one file system:
tumbleweed:~ $ bcachefs format --force /dev/vdb
tumbleweed:~ $ mount /dev/vdb /mnt/dummy/
tumbleweed:~ $ df -h | grep dummy
/dev/vdb 3.7G 2.0M 3.6G 1% /mnt/dummy
Assuming we’re running out of space on that file system and we want to add another device, how does work?
tumbleweed:~ $ bcachefs device add /mnt/dummy/ /dev/vdc
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 2.0M 7.2G 1% /mnt/dummy
Quite easy, and no separate step required to extend the file system, this was done automatically which is quite nice. You can even go a step further and specify how large the file system should be on the new device (which doesn’t make much sense in this case):
tumbleweed:~ $ bcachefs device add --fs_size=4G /mnt/dummy/ /dev/vdd
tumbleweed:~ $ df -h | grep mnt
/dev/vdb:/dev/vdc:/dev/vdd 11G 2.0M 11G 1% /mnt/dummy
Let’s remove this configuration and then create a file system with multiple devices right from the beginning:
tumbleweed:~ $ bcachefs format --force /dev/vdb /dev/vdc
Now we formatted two devices at once, which is great, but how can we mount that? This will obviously not work:
tumbleweed:~ $ mount /dev/vdb /dev/vdc /mnt/dummy/
mount: bad usage
Try 'mount --help' for more information.
The syntax is a bit different, so either do it it with “mount”:
tumbleweed:~ $ mount -t bcachefs /dev/vdb:/dev/vdc /mnt/dummy/
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 2.0M 7.2G 1% /mnt/dummy
… or use the “bcachefs” utility using the same syntax for the list of devices:
tumbleweed:~ $ umount /mnt/dummy
tumbleweed:~ $ bcachefs mount /dev/vdb:/dev/vdc /mnt/dummy/
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 2.0M 7.2G 1% /mnt/dummy
What is a bit annoying is, that you need to know which devices you can still add, as you won’t see this in the “lsblk” output”:
tumbleweed:~ $ lsblk | grep -w "4G"
└─vda3 254:3 0 1.4G 0 part [SWAP]
vdb 254:16 0 4G 0 disk /mnt/dummy
vdc 254:32 0 4G 0 disk
vdd 254:48 0 4G 0 disk
vde 254:64 0 4G 0 disk
vdf 254:80 0 4G 0 disk
vdg 254:96 0 4G 0 disk
You do see it, however in the “df -h” output:
tumbleweed:~ $ df -h | grep dummy
/dev/vdb:/dev/vdc 7.3G 2.0M 7.2G 1% /mnt/dummy
Another way to get those details is once more to use the “bcachefs” utility:
tumbleweed:~ $ bcachefs fs usage /mnt/dummy/
Filesystem: d6f85f8f-dc12-4e83-8547-6fa8312c8eca
Size: 7902739968
Used: 76021760
Online reserved: 0
Data type Required/total Durability Devices
btree: 1/1 1 [vdb] 1048576
btree: 1/1 1 [vdc] 1048576
(no label) (device 0): vdb rw
data buckets fragmented
free: 4256956416 16239
sb: 3149824 13 258048
journal: 33554432 128
btree: 1048576 4
user: 0 0
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 0 0
capacity: 4294967296 16384
(no label) (device 1): vdc rw
data buckets fragmented
free: 4256956416 16239
sb: 3149824 13 258048
journal: 33554432 128
btree: 1048576 4
user: 0 0
cached: 0 0
parity: 0 0
stripe: 0 0
need_gc_gens: 0 0
need_discard: 0 0
capacity: 4294967296 16384
Note that shrinking a file system on a device is currently not supported, only growing.
In the next post we’ll look at how you can mirror your data across multiple devices.
L’article Another file system for Linux: bcachefs (2) – multi device file systems est apparu en premier sur dbi Blog.
Another file system for Linux: bcachefs (1) – basics
When Linux 6.7 (already end of life) was released some time ago another file system made it into the kernel: bcachefs. This is another copy on write file system like ZFS or Btrfs. The goal of this post is not to compare those in regards to features and performance, but just to give you the necessary bits to get started with it. If you want to try this out for yourself, you obviously need at least version 6.7 of the Linux kernel. You can either build it yourself or you can use the distribution of your choice which ships at least with kernel 6.7 as an option. I’ll be using openSUSE Tumbleweed as this is a rolling release and new kernel versions make it into the distribution quite fast after they’ve been released.
When you install Tumbleweed as of today, you’ll get a 6.8 kernel which is fine if you want to play around with bcachefs:
tumbleweed:~ $ uname -a
Linux tumbleweed 6.8.5-1-default #1 SMP PREEMPT_DYNAMIC Thu Apr 11 04:31:19 UTC 2024 (542f698) x86_64 x86_64 x86_64 GNU/Linux
Let’s start very simple: Once device, on file system. Usually you create a new file system with the mkfs command, but you’ll quickly notice that there is nothing for bcachefs:
tumbleweed:~ $ mkfs.[TAB][TAB]
mkfs.bfs mkfs.btrfs mkfs.cramfs mkfs.ext2 mkfs.ext3 mkfs.ext4 mkfs.fat mkfs.minix mkfs.msdos mkfs.ntfs mkfs.vfat
By default there is also no command which starts with “bca”:
tumbleweed:~ # bca[TAB][TAB]
The utilities you need to get started need to be installed on Tumbleweed:
tumbleweed:~ $ zypper se bcachefs
Loading repository data...
Reading installed packages...
S | Name | Summary | Type
--+----------------+--------------------------------------+--------
| bcachefs-tools | Configuration utilities for bcachefs | package
tumbleweed:~ $ zypper in -y bcachefs-tools
Loading repository data...
Reading installed packages...
Resolving package dependencies...
The following 2 NEW packages are going to be installed:
bcachefs-tools libsodium23
2 new packages to install.
Overall download size: 1.4 MiB. Already cached: 0 B. After the operation, additional 3.6 MiB will be used.
Backend: classic_rpmtrans
Continue? [y/n/v/...? shows all options] (y): y
Retrieving: libsodium23-1.0.18-2.16.x86_64 (Main Repository (OSS)) (1/2), 169.7 KiB
Retrieving: libsodium23-1.0.18-2.16.x86_64.rpm ...........................................................................................................[done (173.6 KiB/s)]
Retrieving: bcachefs-tools-1.6.4-1.2.x86_64 (Main Repository (OSS)) (2/2), 1.2 MiB
Retrieving: bcachefs-tools-1.6.4-1.2.x86_64.rpm ............................................................................................................[done (5.4 MiB/s)]
Checking for file conflicts: ...........................................................................................................................................[done]
(1/2) Installing: libsodium23-1.0.18-2.16.x86_64 .......................................................................................................................[done]
(2/2) Installing: bcachefs-tools-1.6.4-1.2.x86_64 ......................................................................................................................[done]
Running post-transaction scripts .......................................................................................................................................[done]
This will give you “mkfs.bcachefs” and all the other utilities you’ll need to play with it.
I’ve prepared six small devices I can play with:
tumbleweed:~ $ lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTS
sr0 11:0 1 276M 0 rom
vda 254:0 0 20G 0 disk
├─vda1 254:1 0 8M 0 part
├─vda2 254:2 0 18.6G 0 part /var
│ /srv
│ /usr/local
│ /opt
│ /root
│ /home
│ /boot/grub2/x86_64-efi
│ /boot/grub2/i386-pc
│ /.snapshots
│ /
└─vda3 254:3 0 1.4G 0 part [SWAP]
vdb 254:16 0 4G 0 disk
vdc 254:32 0 4G 0 disk
vdd 254:48 0 4G 0 disk
vde 254:64 0 4G 0 disk
vdf 254:80 0 4G 0 disk
vdg 254:96 0 4G 0 disk
In the most simple form (one device, one file system) you might start like this:
tumbleweed:~ $ bcachefs format /dev/vdb
External UUID: 127933ff-575b-484f-9eab-d0bf5dbf52b2
Internal UUID: fbf59149-3dc4-4871-bfb5-8fb910d0529f
Magic number: c68573f6-66ce-90a9-d96a-60cf803df7ef
Device index: 0
Label:
Version: 1.6: btree_subvolume_children
Version upgrade complete: 0.0: (unknown version)
Oldest version on disk: 1.6: btree_subvolume_children
Created: Wed Apr 17 10:39:58 2024
Sequence number: 0
Time of last write: Thu Jan 1 01:00:00 1970
Superblock size: 960 B/1.00 MiB
Clean: 0
Devices: 1
Sections: members_v1,members_v2
Features: new_siphash,new_extent_overwrite,btree_ptr_v2,extents_above_btree_updates,btree_updates_journalled,new_varint,journal_no_flush,alloc_v2,extents_across_btree_nodes
Compat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: none
background_compression: none
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
journal_transaction_names: 1
version_upgrade: [compatible] incompatible none
nocow: 0
members_v2 (size 144):
Device: 0
Label: (none)
UUID: bb28c803-621a-4007-af13-a9218808de8f
Size: 4.00 GiB
read errors: 0
write errors: 0
checksum errors: 0
seqread iops: 0
seqwrite iops: 0
randread iops: 0
randwrite iops: 0
Bucket size: 256 KiB
First bucket: 0
Buckets: 16384
Last mount: (never)
Last superblock write: 0
State: rw
Data allowed: journal,btree,user
Has data: (none)
Durability: 1
Discard: 0
Freespace initialized: 0
mounting version 1.6: btree_subvolume_children
initializing new filesystem
going read-write
initializing freespace
This is already ready to mount and we have our first bcachfs file system:
tumbleweed:~ $ mkdir /mnt/dummy
tumbleweed:~ $ mount /dev/vdb /mnt/dummy
tumbleweed:~ $ df -h | grep dummy
/dev/vdb 3.7G 2.0M 3.6G 1% /mnt/dummy
If you need encryption, this is supported as well and obviously is asking you for a passphrase when you format the device:
tumbleweed:~ $ umount /mnt/dummy
tumbleweed:~ $ bcachefs format --encrypted --force /dev/vdb
Enter passphrase:
Enter same passphrase again:
/dev/vdb contains a bcachefs filesystem
External UUID: aa0a4742-46ed-4228-a590-62b8e2de7633
Internal UUID: 800b2306-3900-47fb-9a42-2f7e75baec99
Magic number: c68573f6-66ce-90a9-d96a-60cf803df7ef
Device index: 0
Label:
Version: 1.4: member_seq
Version upgrade complete: 0.0: (unknown version)
Oldest version on disk: 1.4: member_seq
Created: Wed Apr 17 10:46:06 2024
Sequence number: 0
Time of last write: Thu Jan 1 01:00:00 1970
Superblock size: 1.00 KiB/1.00 MiB
Clean: 0
Devices: 1
Sections: members_v1,crypt,members_v2
Features:
Compat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: none
background_compression: none
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
journal_transaction_names: 1
version_upgrade: [compatible] incompatible none
nocow: 0
members_v2 (size 144):
Device: 0
Label: (none)
UUID: 60de61d2-391b-4605-b0da-5f593b7c703f
Size: 4.00 GiB
read errors: 0
write errors: 0
checksum errors: 0
seqread iops: 0
seqwrite iops: 0
randread iops: 0
randwrite iops: 0
Bucket size: 256 KiB
First bucket: 0
Buckets: 16384
Last mount: (never)
Last superblock write: 0
State: rw
Data allowed: journal,btree,user
Has data: (none)
Durability: 1
Discard: 0
Freespace initialized: 0
To mount this you’ll need to specify the passphrase given above or it will fail:
tumbleweed:~ $ mount /dev/vdb /mnt/dummy/
Enter passphrase:
ERROR - bcachefs::commands::cmd_mount: Fatal error: failed to verify the password
tumbleweed:~ $ mount /dev/vdb /mnt/dummy/
Enter passphrase:
tumbleweed:~ $ df -h | grep dummy
/dev/vdb 3.7G 2.0M 3.6G 1% /mnt/dummy
tumbleweed:~ $ umount /mnt/dummy
Beside encryption you may also use compression (supported are gzip, lz4 and zstd), e.g.:
tumbleweed:~ $ bcachefs format --compression=lz4 --force /dev/vdb
/dev/vdb contains a bcachefs filesystem
External UUID: 1ebcfe14-7d6a-43b1-8d48-47bcef0e7021
Internal UUID: 5117240c-95f1-4c2a-bed4-afb4c4fbb83c
Magic number: c68573f6-66ce-90a9-d96a-60cf803df7ef
Device index: 0
Label:
Version: 1.4: member_seq
Version upgrade complete: 0.0: (unknown version)
Oldest version on disk: 1.4: member_seq
Created: Wed Apr 17 10:54:02 2024
Sequence number: 0
Time of last write: Thu Jan 1 01:00:00 1970
Superblock size: 960 B/1.00 MiB
Clean: 0
Devices: 1
Sections: members_v1,members_v2
Features:
Compat features:
Options:
block_size: 512 B
btree_node_size: 256 KiB
errors: continue [ro] panic
metadata_replicas: 1
data_replicas: 1
metadata_replicas_required: 1
data_replicas_required: 1
encoded_extent_max: 64.0 KiB
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
compression: lz4
background_compression: none
str_hash: crc32c crc64 [siphash]
metadata_target: none
foreground_target: none
background_target: none
promote_target: none
erasure_code: 0
inodes_32bit: 1
shard_inode_numbers: 1
inodes_use_key_cache: 1
gc_reserve_percent: 8
gc_reserve_bytes: 0 B
root_reserve_percent: 0
wide_macs: 0
acl: 1
usrquota: 0
grpquota: 0
prjquota: 0
journal_flush_delay: 1000
journal_flush_disabled: 0
journal_reclaim_delay: 100
journal_transaction_names: 1
version_upgrade: [compatible] incompatible none
nocow: 0
members_v2 (size 144):
Device: 0
Label: (none)
UUID: 3bae44f0-3cd4-4418-8556-4342e74c22d1
Size: 4.00 GiB
read errors: 0
write errors: 0
checksum errors: 0
seqread iops: 0
seqwrite iops: 0
randread iops: 0
randwrite iops: 0
Bucket size: 256 KiB
First bucket: 0
Buckets: 16384
Last mount: (never)
Last superblock write: 0
State: rw
Data allowed: journal,btree,user
Has data: (none)
Durability: 1
Discard: 0
Freespace initialized: 0
tumbleweed:~ $ mount /dev/vdb /mnt/dummy/
tumbleweed:~ $ df -h | grep dummy
/dev/vdb 3.7G 2.0M 3.6G 1% /mnt/dummy
Meta data and data check sums are enabled by default:
tumbleweed:~ $ bcachefs show-super -l /dev/vdb | grep -i check
metadata_checksum: none [crc32c] crc64 xxhash
data_checksum: none [crc32c] crc64 xxhash
checksum errors: 0
That’s it for the very basics. In the next post we’ll look at multi device file systems.
L’article Another file system for Linux: bcachefs (1) – basics est apparu en premier sur dbi Blog.
Build SQL Server audit reports with Powershell
When you are tasked with conducting an audit at a client’s site or on the environment you manage, you might find it necessary to automate the audit process in order to save time. However, it can be challenging to extract information from either the PowerShell console or a text file.
Here, the idea would be to propose a solution that could generate audit reports to quickly identify how the audited environment is configured. We will attempt to propose a solution that will automate the generation of audit reports.
In broad terms, here are what we will implement:
- Define the environment we wish to audit. We centralize the configuration of our environments and all the parameters we will use.
- Define the checks or tests we would like to perform.
- Execute these checks. In our case, we will mostly use dbatools to perform the checks. However, it’s possible that you may not be able to use dbatools in your environment for security reasons, for example. In that case, you could replace calls to dbatools with calls to PowerShell functions.
- Produce an audit report.
Here are the technologies we will use in our project :
- SQL Server
- Powershell
- Windows Server
- XML, XSLT and JSON
In our example, we use the dbatools module in oder to get some information related to the environment(s) we audit.
Reference : https://dbatools.io/
Global architectureHere is how our solution will work :
- We store the configuration of our environment in a JSON file. This avoids storing certain parameters in the PowerShell code.
- We import our configuration (our JSON file). We centralize in one file all the checks, tests to be performed. The configuration stored in the JSON file is passed to the tests.
- We execute all the tests to be performed, then we generate an HTML file (applying an XSLT style sheet) from the collected information.
- We can then send this information by email (for example).
Here are some details about the structure of our project :
FolderTypeFileDescriptionDetailsdbi-auditPS1 filedbi-audit-config.jsonContains some pieces of information related to the environment you would like to audit.The file is called by the dbi-audit-checks.ps1. We import that file and parse it. E.g. if you need to add new servers to audit you can edit that file and run a new audit.dbi-auditPS1 filedbi-audit-checks.ps1Store the checks to perform on the environment(s).That file acts as a “library”, it contains all the checks to perform. It centralizes all the functions.dbi-auditPS1 filedbi-audit-run.ps1Run the checks to perform Transform the output in an html file.It’s the most import file :It runs the checks to perform.
It builds the html report and apply a stylesheet
It can also send by email the related reportdbi-auditXSL filedbi-audit-stylesheet.xslContains the stylesheet to apply to the HTML report.It’s where you will define what you HTML report will look like.html_outputFolder–Will contain the report audit produced.It stores HTML reports.
What does it look like ?
How does it work ?
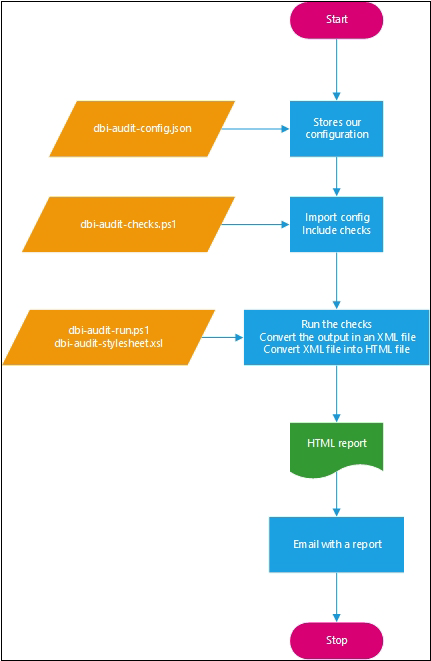 Implementation
Implementation
Code – A basic implementation :
dbi-audit-config.json :
[
{
"Name": "dbi-app.computername",
"Value": [
"TEST-SQL"
],
"Description": "Windows servers list to audit"
},
{
"Name": "dbi-app.sqlinstance",
"Value": [
"TEST-SQL\\INSTANCEA"
],
"Description": "SQL Server list to audit"
},
{
"Name": "dbi-app.checkcomputersinformation.enabled",
"Value": "True",
"Description": "Get some information on OS level"
},
{
"Name": "dbi-app.checkoperatingsystem.enabled",
"Value": "True",
"Description": "Perform some OS checks"
},
{
"Name": "dbi-app.checksqlsystemconfiguration.enabled",
"Value": "True",
"Description": "Check some SQL Server system settings"
}
]dbi-audit-checks.ps1 :
#We import our configuration
$AuditConfig = [PSCustomObject](Get-Content .\dbi-audit-config.json | Out-String | ConvertFrom-Json)
#We retrieve the values contained in our json file. Each value is stored in a variable
$Computers = $AuditConfig | Where-Object { $_.Name -eq 'dbi-app.computername' } | Select-Object Value
$SQLInstances = $AuditConfig | Where-Object { $_.Name -eq 'dbi-app.sqlinstance' } | Select-Object Value
$UnitFileSize = ($AuditConfig | Where-Object { $_.Name -eq 'app.unitfilesize' } | Select-Object Value).Value
#Our configuration file allow to enable or disable some checks. We also retrieve those values.
$EnableCheckComputersInformation = ($AuditConfig | Where-Object { $_.Name -eq 'dbi-app.checkcomputersinformation.enabled' } | Select-Object Value).Value
$EnableCheckOperatingSystem = ($AuditConfig | Where-Object { $_.Name -eq 'dbi-app.checkoperatingsystem.enabled' } | Select-Object Value).Value
$EnableCheckSQLSystemConfiguration = ($AuditConfig | Where-Object { $_.Name -eq 'dbi-app.checksqlsystemconfiguration.enabled' } | Select-Object Value).Value
#Used to invoke command queries
$ComputersList = @()
$ComputersList += $Computers | Foreach-Object {
$_.Value
}
<#
Get Computer Information
#>
function CheckComputersInformation()
{
if ($EnableCheckComputersInformation)
{
$ComputersInformationList = @()
$ComputersInformationList += $Computers | Foreach-Object {
Get-DbaComputerSystem -ComputerName $_.Value |
Select-Object ComputerName, Domain, NumberLogicalProcessors,
NumberProcessors, TotalPhysicalMemory
}
}
return $ComputersInformationList
}
<#
Get OS Information
#>
function CheckOperatingSystem()
{
if ($EnableCheckOperatingSystem)
{
$OperatingSystemList = @()
$OperatingSystemList += $Computers | Foreach-Object {
Get-DbaOperatingSystem -ComputerName $_.Value |
Select-Object ComputerName, Architecture, OSVersion, ActivePowerPlan
}
}
return $OperatingSystemList
}
<#
Get SQL Server/OS Configuration : IFI, LockPagesInMemory
#>
function CheckSQLSystemConfiguration()
{
if ($EnableCheckSQLSystemConfiguration)
{
$SQLSystemConfigurationList = @()
$SQLSystemConfigurationList += $Computers | Foreach-Object {
$ComputerName = $_.Value
Get-DbaPrivilege -ComputerName $ComputerName |
Where-Object { $_.User -like '*MSSQL*' } |
Select-Object ComputerName, User, InstantFileInitialization, LockPagesInMemory
$ComputerName = $Null
}
}
return $SQLSystemConfigurationList
}
dbi-audit-run.ps1 :
#Our configuration file will accept a parameter. It's the stylesheet to apply to our HTML report
Param(
[parameter(mandatory=$true)][string]$XSLStyleSheet
)
# We import the checks to run
. .\dbi-audit-checks.ps1
#Setup the XML configuration
$ScriptLocation = Get-Location
$XslOutputPath = "$($ScriptLocation.Path)\$($XSLStyleSheet)"
$FileSavePath = "$($ScriptLocation.Path)\html_output"
[System.XML.XMLDocument]$XmlOutput = New-Object System.XML.XMLDocument
[System.XML.XMLElement]$XmlRoot = $XmlOutput.CreateElement("DbiAuditReport")
$Null = $XmlOutput.appendChild($XmlRoot)
#We run the checks. Instead of manually call all the checks, we store them in array
#We browse that array and we execute the related function
#Each function result is used and append to the XML structure we build
$FunctionsName = @("CheckComputersInformation", "CheckOperatingSystem", "CheckSQLSystemConfiguration")
$FunctionsStore = [ordered] @{}
$FunctionsStore['ComputersInformation'] = CheckComputersInformation
$FunctionsStore['OperatingSystem'] = CheckOperatingSystem
$FunctionsStore['SQLSystemConfiguration'] = CheckSQLSystemConfiguration
$i = 0
$FunctionsStore.Keys | ForEach-Object {
[System.XML.XMLElement]$xmlSQLChecks = $XmlRoot.appendChild($XmlOutput.CreateElement($FunctionsName[$i]))
$Results = $FunctionsStore[$_]
foreach ($Data in $Results)
{
$xmlServicesEntry = $xmlSQLChecks.appendChild($XmlOutput.CreateElement($_))
foreach ($DataProperties in $Data.PSObject.Properties)
{
$xmlServicesEntry.SetAttribute($DataProperties.Name, $DataProperties.Value)
}
}
$i++
}
#We create our XML file
$XmlRoot.SetAttribute("EndTime", (Get-Date -Format yyyy-MM-dd_h-mm))
$ReportXMLFileName = [string]::Format("{0}\{1}_DbiAuditReport.xml", $FileSavePath, (Get-Date).tostring("MM-dd-yyyy_HH-mm-ss"))
$ReportHTMLFileName = [string]::Format("{0}\{1}_DbiAuditReport.html", $FileSavePath, (Get-Date).tostring("MM-dd-yyyy_HH-mm-ss"))
$XmlOutput.Save($ReportXMLFileName)
#We apply our XSLT stylesheet
[System.Xml.Xsl.XslCompiledTransform]$XSLT = New-Object System.Xml.Xsl.XslCompiledTransform
$XSLT.Load($XslOutputPath)
#We build our HTML file
$XSLT.Transform($ReportXMLFileName, $ReportHTMLFileName)dbi-audit-stylesheet.xsl :
<xsl:stylesheet xmlns:xsl="http://www.w3.org/1999/XSL/Transform" version="1.0">
<xsl:template match="DbiAuditReport">
<xsl:text disable-output-escaping='yes'><!DOCTYPE html></xsl:text>
<html>
<head>
<meta http-equiv="X-UA-Compatible" content="IE=9" />
<style>
body {
font-family: Verdana, sans-serif;
font-size: 15px;
line-height: 1.5M background-color: #FCFCFC;
}
h1 {
color: #EB7D00;
font-size: 30px;
}
h2 {
color: #004F9C;
margin-left: 2.5%;
}
h3 {
font-size: 24px;
}
table {
width: 95%;
margin: auto;
border: solid 2px #D1D1D1;
border-collapse: collapse;
border-spacing: 0;
margin-bottom: 1%;
}
table tr th {
background-color: #D1D1D1;
border: solid 1px #D1D1D1;
color: #004F9C;
padding: 10px;
text-align: left;
text-shadow: 1px 1px 1px #fff;
}
table td {
border: solid 1px #DDEEEE;
color: #004F9C;
padding: 10px;
text-shadow: 1px 1px 1px #fff;
}
table tr:nth-child(even) {
background: #F7F7F7
}
table tr:nth-child(odd) {
background: #FFFFFF
}
table tr .check_failed {
color: #F7F7F7;
background-color: #FC1703;
}
table tr .check_passed {
color: #F7F7F7;
background-color: #16BA00;
}
table tr .check_in_between {
color: #F7F7F7;
background-color: #F5B22C;
}
</style>
</head>
<body>
<table>
<tr>
<td>
<h1>Audit report</h1> </td>
</tr>
</table>
<caption>
<xsl:apply-templates select="CheckComputersInformation" />
<xsl:apply-templates select="CheckOperatingSystem" />
<xsl:apply-templates select="CheckSQLSystemConfiguration" /> </caption>
</body>
</html>
</xsl:template>
<xsl:template match="CheckComputersInformation">
<h2>Computer Information</h2>
<table>
<tr>
<th>Computer Name</th>
<th>Domain</th>
<th>Number Logical Processors</th>
<th>Number Processors</th>
<th>Total Physical Memory</th>
</tr>
<tbody>
<xsl:apply-templates select="ComputersInformation" /> </tbody>
</table>
</xsl:template>
<xsl:template match="ComputersInformation">
<tr>
<td>
<xsl:value-of select="@ComputerName" />
</td>
<td>
<xsl:value-of select="@Domain" />
</td>
<td>
<xsl:value-of select="@NumberLogicalProcessors" />
</td>
<td>
<xsl:value-of select="@NumberProcessors" />
</td>
<td>
<xsl:value-of select="@TotalPhysicalMemory" />
</td>
</tr>
</xsl:template>
<xsl:template match="CheckOperatingSystem">
<h2>Operating System</h2>
<table>
<tr>
<th>Computer Name</th>
<th>Architecture</th>
<th>OS Version</th>
<th>Power Plan</th>
</tr>
<tbody>
<xsl:apply-templates select="OperatingSystem" /> </tbody>
</table>
</xsl:template>
<xsl:template match="OperatingSystem">
<tr>
<td>
<xsl:value-of select="@ComputerName" />
</td>
<td>
<xsl:value-of select="@Architecture" />
</td>
<td>
<xsl:value-of select="@OSVersion" />
</td>
<xsl:choose>
<xsl:when test="@ActivePowerPlan = 'High performance'">
<td class="check_passed">
<xsl:value-of select="@ActivePowerPlan" />
</td>
</xsl:when>
<xsl:otherwise>
<td class="check_failed">
<xsl:value-of select="@ActivePowerPlan" />
</td>
</xsl:otherwise>
</xsl:choose>
</tr>
</xsl:template>
<xsl:template match="CheckSQLSystemConfiguration">
<h2>SQL System Configuration</h2>
<table>
<tr>
<th>Computer Name</th>
<th>User</th>
<th>Instant File Initialization</th>
<th>Lock Pages In Memory</th>
</tr>
<tbody>
<xsl:apply-templates select="SQLSystemConfiguration" /> </tbody>
</table>
</xsl:template>
<xsl:template match="SQLSystemConfiguration">
<tr>
<td>
<xsl:value-of select="@ComputerName" />
</td>
<td>
<xsl:value-of select="@User" />
</td>
<xsl:choose>
<xsl:when test="@InstantFileInitialization = 'True'">
<td class="check_passed">
<xsl:value-of select="@InstantFileInitialization" />
</td>
</xsl:when>
<xsl:otherwise>
<td class="check_failed">
<xsl:value-of select="@InstantFileInitialization" />
</td>
</xsl:otherwise>
</xsl:choose>
<xsl:choose>
<xsl:when test="@LockPagesInMemory = 'True'">
<td class="check_passed">
<xsl:value-of select="@LockPagesInMemory" />
</td>
</xsl:when>
<xsl:otherwise>
<td class="check_in_between">
<xsl:value-of select="@LockPagesInMemory" />
</td>
</xsl:otherwise>
</xsl:choose>
</tr>
</xsl:template>
</xsl:stylesheet>How does it run ?
.\dbi-audit-run.ps1 -XSLStyleSheet .\dbi-audit-stylesheet.xslOutput (what does it really look like ?) :
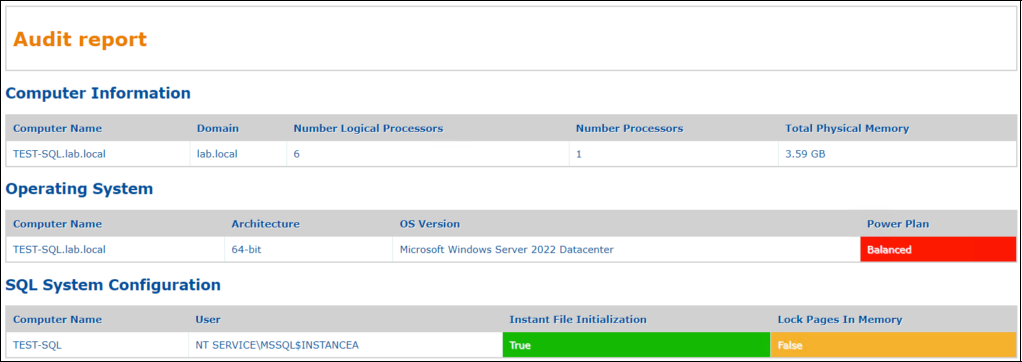 Nice to have
Nice to have
Let’s say I would like to add new checks. How would I proceed ?
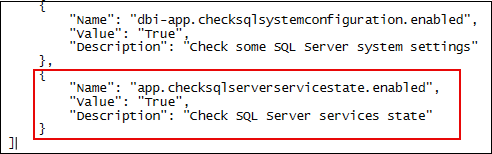
- Edit the dbi-audit-checks.ps1
- Retrieve the information related to your check
$EnableCheckSQLServerServiceState = ($AuditConfig | Where-Object { $_.Name -eq 'app.checksqlserverservicestate.enabled' } | Select-Object Value).Value- Add another function
function CheckSQLServerServiceState()
{
if ($EnableCheckSQLServerServiceState -eq $True)
{
$SQLServerServiceStateList = @()
$SQLServerServiceStateList += $Computers | Foreach-Object {
Get-DbaService -ComputerName $_.Value |
Select-Object ComputerName, ServiceName, ServiceType, DisplayName, StartName, State, StartMode
}
}
return $SQLServerServiceStateList
}- Call it in the dbi-audit-run script
$FunctionsName = @("CheckComputersInformation", "CheckOperatingSystem", "CheckSQLSystemConfiguration", "CheckSQLServerServiceState")
$FunctionsStore = [ordered] @{}
$FunctionsStore['ComputersInformation'] = CheckComputersInformation
$FunctionsStore['OperatingSystem'] = CheckOperatingSystem
$FunctionsStore['SQLSystemConfiguration'] = CheckSQLSystemConfiguration
$FunctionsStore['SQLServerServiceState'] = CheckSQLServerServiceStateEdit the dbi-audit-stylesheet.xsl to include how you would like to display the information you collected (it’s the most consuming time part because it’s not automated. I did not find a way to automate it yet)
<body>
<table>
<tr>
<td>
<h1>Audit report</h1>
</td>
</tr>
</table>
<caption>
<xsl:apply-templates select="CheckComputersInformation"/>
<xsl:apply-templates select="CheckOperatingSystem"/>
<xsl:apply-templates select="CheckSQLSystemConfiguration"/>
<xsl:apply-templates select="CheckSQLServerServiceState"/>
</caption>
</body>
...
<xsl:template match="CheckSQLServerServiceState">
<h2>SQL Server Services State</h2>
<table>
<tr>
<th>Computer Name</th>
<th>Service Name</th>
<th>Service Type</th>
<th>Display Name</th>
<th>Start Name</th>
<th>State</th>
<th>Start Mode</th>
</tr>
<tbody>
<xsl:apply-templates select="SQLServerServiceState"/>
</tbody>
</table>
</xsl:template>
<xsl:template match="SQLServerServiceState">
<tr>
<td><xsl:value-of select="@ComputerName"/></td>
<td><xsl:value-of select="@ServiceName"/></td>
<td><xsl:value-of select="@ServiceType"/></td>
<td><xsl:value-of select="@DisplayName"/></td>
<td><xsl:value-of select="@StartName"/></td>
<xsl:choose>
<xsl:when test="(@State = 'Stopped') and (@ServiceType = 'Engine')">
<td class="check_failed"><xsl:value-of select="@State"/></td>
</xsl:when>
<xsl:when test="(@State = 'Stopped') and (@ServiceType = 'Agent')">
<td class="check_failed"><xsl:value-of select="@State"/></td>
</xsl:when>
<xsl:otherwise>
<td class="check_passed"><xsl:value-of select="@State"/></td>
</xsl:otherwise>
</xsl:choose>
<td><xsl:value-of select="@StartMode"/></td>
</tr>
</xsl:template>End result :
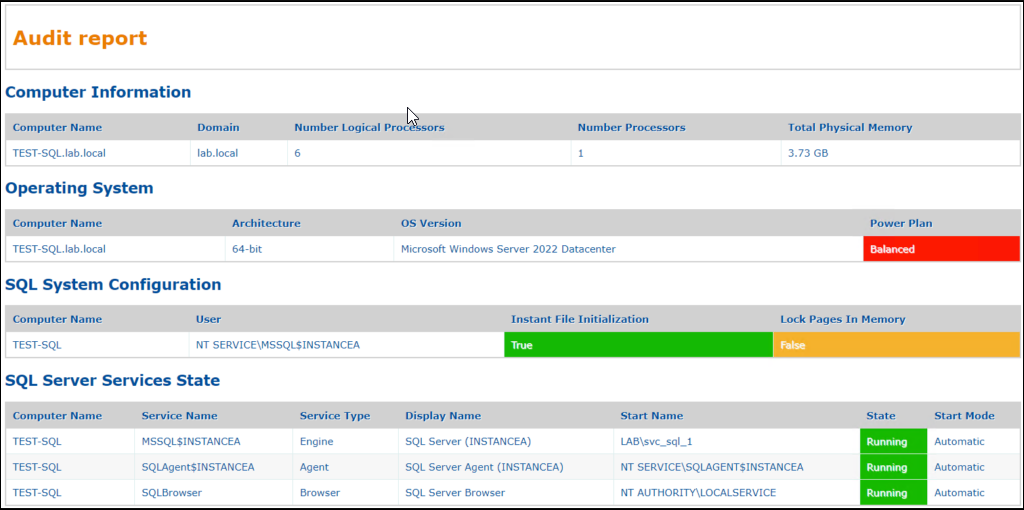
What about sending the report through email ?
- We could add a function that send an email with an attachment.
- Edit the dbi-audit-checks file
- Add a function Send-EmailWithAuditReport
- Add this piece of code to the function :
- Edit the dbi-audit-checks file
Send-MailMessage -SmtpServer mysmtpserver -From 'Sender' -To 'Recipient' -Subject 'Audit report' -Body 'Audit report' -Port 25 -Attachments $Attachments- Edit the dbi-audit-run.ps1
- Add a call to the Send-EmailWithAuditReport function :
Send-EmailWithAuditReport -Attachments $Attachments
- Add a call to the Send-EmailWithAuditReport function :
$ReportHTMLFileName = [string]::Format("{0}\{1}_DbiAuditReport.html", $FileSavePath, (Get-Date).tostring("MM-dd-yyyy_HH-mm-ss"))
...
SendEmailsWithReport -Attachments $ReportHTMLFileName
The main idea of this solution is to be able to use the same functions while applying a different rendering. To achieve this, you would need to change the XSL stylesheet or create another XSL stylesheet and then provide to the dbi-audit-run.ps1 file the stylesheet to apply.
This would allow having the same code to perform the following tasks:
- Audit
- Health check
- …
L’article Build SQL Server audit reports with Powershell est apparu en premier sur dbi Blog.
Rancher RKE2: Rancher roles for cluster autoscaler
The cluster autoscaler brings horizontal scaling into your cluster by deploying it into the cluster to autoscale. This is described in the following blog article https://www.dbi-services.com/blog/rancher-autoscaler-enable-rke2-node-autoscaling/. It didn’t emphasize much about the user and role configuration.
With Rancher, the cluster autoscaler uses a user’s API key. We will see how to configure minimal permissions by creating Rancher roles for cluster autoscaler.
Rancher userFirst, let’s create the user that will communicate with Rancher, and whose token will be used. It will be given minimal access rights which is login access.
Go to Rancher > Users & Authentication > Users > Create.
- Set a username, for example, autoscaler
- Set the password
- Give User-Base permissions
- Create
The user is now created, let’s set Rancher roles with minimal permission for the cluster autoscaler.
Rancher roles authorizationTo make the cluster autoscaler work, the user whose API key is provided needs the following roles:
- Cluster role (for the cluster to autoscale)
Get/Update for clusters.provisioning.cattle.io
Update of machines.cluster.x-k8s.io - Project role (for the namespace that contains the cluster resource (fleet-default))
Get/List of machines.cluster.x-k8s.io
Go to Rancher > Users & Authentication > Role Templates > Cluster > Create.
Create the cluster role. This role will be applied to every cluster that we want to autoscale.
Then in Rancher > Users & Authentication > Role Templates > Project/Namespaces > Create.
Create the project role, it will be applied to the project of our local cluster (Rancher) that contains the namespace fleet-default.
 Rancher roles assignment
Rancher roles assignment
The user and Rancher roles are created, let’s assign them.
Project roleFirst, we will set the project role, this is to be done once.
Go to the local cluster (Rancher), in Cluster > Project/Namespace.
Search for the fleet-default namespace, by default it is contained in the project System.
Edit the project System and add the user with the project permissions created precedently.
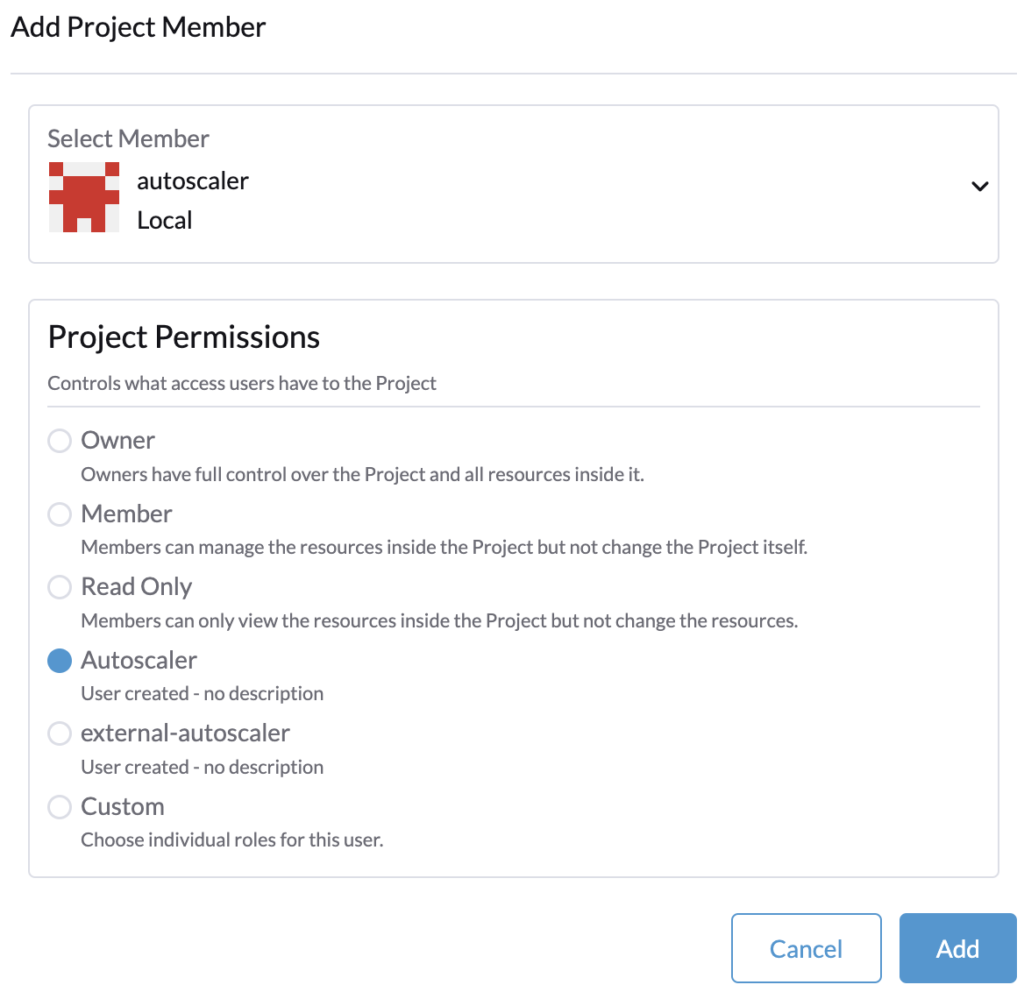
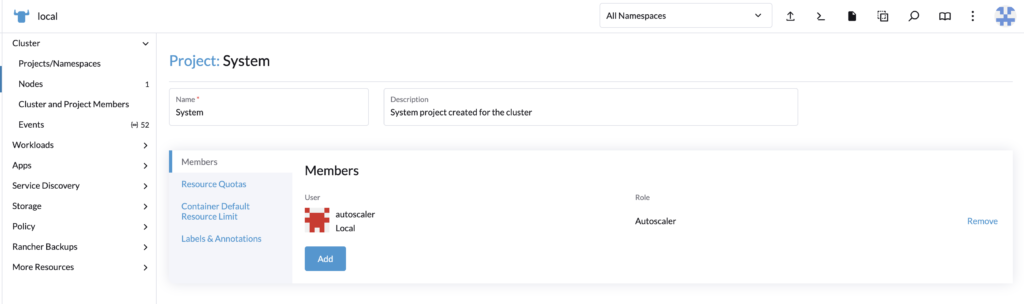 Cluster role
Cluster role
For each cluster where you will deploy the cluster autoscaler, you need to assign the user as a member with the cluster role.
In Rancher > Cluster Management, edit the cluster’s configuration and assign the user.
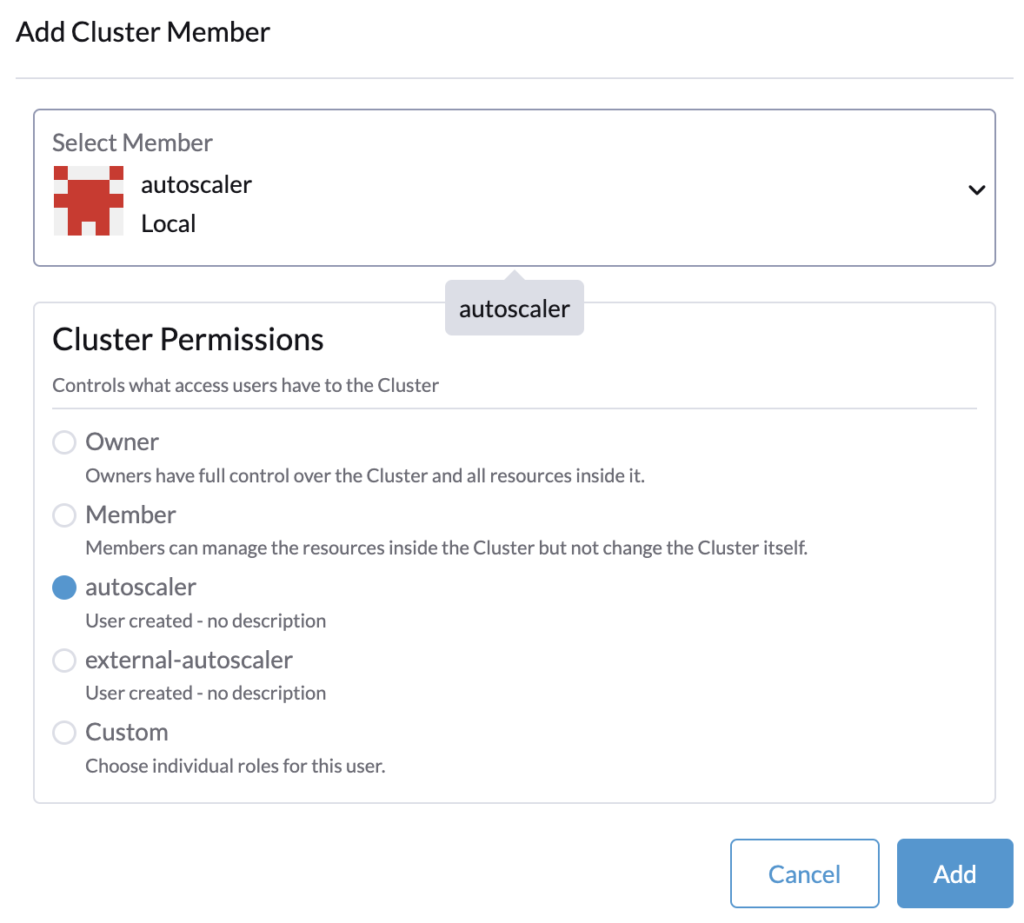
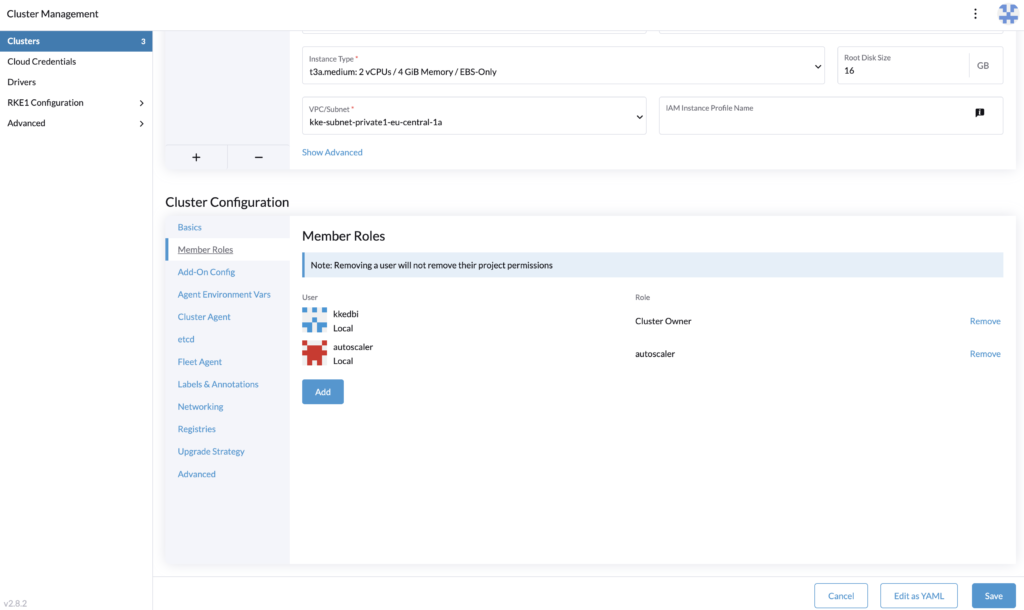
The roles assignment is done, let’s proceed to generate the token that is provided to the cluster autoscaler configuration.
Rancher API keysLog in with the autoscaler user, and go to its profile > Account & API Keys.
Let’s create an API Key for the cluster autoscaler configuration. Note that in a recent update of Rancher, the API keys expired by default in 90 days.
If you see this limitation, you can do the following steps to have no expiration.
With the admin account, in Global settings > Settings, search for the setting auth-token-max-ttl-minutes and set it to 0.

Go back with the autoscaler user and create the API Key, name it for example, autoscaler, and select “no scope”.
You can copy the Bearer Token, and use it for the cluster autoscaler configuration.
As seen above, the token never expires.
Let’s reset the parameter auth-token-max-ttl-minutes and use the default value button or the precedent value set.
We are now done with the roles configuration.
ConclusionThis blog article covers only a part of the setup for the cluster autoscaler for RKE2 provisioning. It explained the configuration of a Rancher user and Rancher’s roles with minimal permissions to enable the cluster autoscaler. It was made to complete this blog article https://www.dbi-services.com/blog/rancher-autoscaler-enable-rke2-node-autoscaling/ which covers the whole setup and deployment of the cluster autoscaler. Therefore if you are still wondering how to deploy and make the cluster autoscaler work, check the other blog.
LinksRancher official documentation: Rancher
RKE2 official documentation: RKE2
GitHub cluster autoscaler: https://github.com/kubernetes/autoscaler/tree/master/cluster-autoscaler
Blog – Rancher autoscaler – Enable RKE2 node autoscaling
https://www.dbi-services.com/blog/rancher-autoscaler-enable-rke2-node-autoscaling
Blog – Reestablish administrator role access to Rancher users
https://www.dbi-services.com/blog/reestablish-administrator-role-access-to-rancher-users/
Blog – Introduction and RKE2 cluster template for AWS EC2
https://www.dbi-services.com/blog/rancher-rke2-cluster-templates-for-aws-ec2
Blog – Rancher RKE2 templates – Assign members to clusters
https://www.dbi-services.com/blog/rancher-rke2-templates-assign-members-to-clusters
L’article Rancher RKE2: Rancher roles for cluster autoscaler est apparu en premier sur dbi Blog.
Elasticsearch, Ingest Pipeline and Machine Learning
Elasticsearch has few interesting features around Machine Learning. While I was looking for data to import into Elasticsearch, I found interesting data sets from Airbnb especially reviews. I noticed that it does not contain any rate, but only comments.
To have sentiment of the a review, I would rather have an opinion on that review like:
- Negative
- Positive
- Neutral
For that matter, I found the cardiffnlp/twitter-roberta-base-sentiment-latest to suite my needs for my tests.
Import ModelElasticsearch provides the tool to import models from Hugging face into Elasticsearch itself: eland.
It is possible to install it or even use the pre-built docker image:
docker run -it --rm --network host docker.elastic.co/eland/eland
Let’s import the model:
eland_import_hub_model -u elastic -p 'password!' --hub-model-id cardiffnlp/twitter-roberta-base-sentiment-latest --task-type classification --url https://127.0.0.1:9200
After a minute, import completes:
2024-04-16 08:12:46,825 INFO : Model successfully imported with id 'cardiffnlp__twitter-roberta-base-sentiment-latest'
I can also check that it was imported successfully with the following API call:
GET _ml/trained_models/cardiffnlp__twitter-roberta-base-sentiment-latest
And result (extract):
{
"count": 1,
"trained_model_configs": [
{
"model_id": "cardiffnlp__twitter-roberta-base-sentiment-latest",
"model_type": "pytorch",
"created_by": "api_user",
"version": "12.0.0",
"create_time": 1713255117150,
...
"description": "Model cardiffnlp/twitter-roberta-base-sentiment-latest for task type 'text_classification'",
"tags": [],
...
},
"classification_labels": [
"negative",
"neutral",
"positive"
],
...
]
}
Next, model must be started:
POST _ml/trained_models/cardiffnlp__twitter-roberta-base-sentiment-latest/deployment/_start
This is subject to licensing. You might face this error “current license is non-compliant for [ml]“. For my tests, I used a trial.
I will use Filebeat to read review.csv file and ingest it into Elasticsearch. filebeat.yml looks like this:
filebeat.inputs:
- type: log
paths:
- 'C:\csv_inject\*.csv'
output.elasticsearch:
hosts: ["https://localhost:9200"]
protocol: "https"
username: "elastic"
password: "password!"
ssl:
ca_trusted_fingerprint: fakefp4076a4cf5c1111ac586bafa385exxxxfde0dfe3cd7771ed
indices:
- index: "csv"
pipeline: csv
So each time a new file gets into csv_inject folder, Filebeat will parse it and send it to my Elasticsearch setup within csv index.
PipelineIngest pipeline can perform basic transformation to incoming data before being indexed.
Data transformationFirst step consists of converting message field, which contains one line of data, into several target fields (ie. split csv). Next, remove message field. This looks like this in Processors section of the Ingest pipeline:
Next, I also want to replace the content of the default timestamp field (ie. @timestamp) with the timestamp of the review (and remove the date field after that):
 Inference
Inference
Now, I add the Inference step:

The only customization of that step is the field map as the default input field name is “text_field“, In the reviews, fields is named “comment“:
Optionally, but recommended, it is possible to add Failure processors which will set a field to keep track of the cause and will put them in a different index:
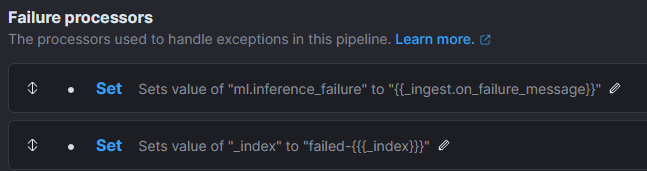 Ingest
Ingest
Now, I can simply copy the review.csv into the watched directory and Filebeat will send lines to Elasticsearch. After few minutes, I can see the first results:

Or, a considered negative example with the associated prediction rate:
 What Next?
What Next?
Of course, we could try another model to compare results.
If you did not noticed, this was also a first step into Extract-transform-load topic (ETL).
L’article Elasticsearch, Ingest Pipeline and Machine Learning est apparu en premier sur dbi Blog.
Learning Azure by having fun with ChatGPT
Are you studying for an Azure certification? You may feel at some point you need a break from the dry and factual technical information. I’m in your shoes right now and I have done some experiments with ChatGPT. I’m not using it to write my text but to learn by having fun! It is very good at telling stories so why not use that for what interests me right now? Azure architecture!
In this blog post I’m going to show you how I use it, it may give you some ideas to make your learning a little more spicy!
 Prompt for preparing ChatGPT with Azure
Prompt for preparing ChatGPT with Azure
First you’ll need to prepare ChatGPT by explaining what you want. Set the framework and limit its responses otherwise it is too chatty. As I like science fiction (sci-fi), I’m interested in a futuristic story but you could choose any style you like. My first prompt and ChatGPT response is shown below:
Act as an Azure architect. You are in charge of educating me, your student, to become an Azure architect too. You will respond to my questions by using story telling to explain each concepts requested.
I want you to:
– Always tell a simple and futuristic story
– Limit the reply to 100 words
As an Azure architect, imagine Azure as a vast cosmic city. Each service is a towering skyscraper, and we, architects, design the blueprints. Let’s start with Virtual Networks. They’re like the city’s infrastructure, connecting buildings. Subnets divide areas within each building, like floors. Next, VMs are the inhabitants, residing in these skyscrapers, each serving a unique purpose. Azure Storage, a network of secure vaults, safeguards their belongings. With Azure Load Balancer as traffic controllers, the city thrives, ensuring smooth navigation. As architects of this digital metropolis, we sculpt a future where innovation soars amidst the azure skyline.
Not bad! It gives me some key components of an Azure infrastructure and makes some analogies I can easily picture in my head. With this basis, I can now be the hero of this story by asking more questions.
Build up that Azure cosmic city with ChatGPTYou can then ask questions around your area of study (mine is Azure architecture) and stay immersed into that story. For example:
What are the best practice to govern this Azure cosmic city?
In our cosmic city, governance is paramount. Azure Policy acts as the city’s constitution, ensuring compliance with regulations. Role-Based Access Control (RBAC) assigns roles to citizens, granting appropriate permissions. Azure Resource Manager templates are like city blueprints, ensuring consistency in construction. Tags label buildings for easy identification, while Azure Monitor keeps a watchful eye on city activities. With these best practices, our cosmic city thrives, ensuring order, security, and harmony amidst the azure skyline.It gives you the key elements of Azure governance by continuing its story. You can go on like this back and forth by throwing in any chapter of your course. You can focus on a specific use case as well and see how it integrates with this story:
How can I migrate my SQL Server database on-premises to this city?
Imagine your SQL Server database as a cozy cottage in the countryside. To migrate to our cosmic city, Azure, we’ll use Azure Database Migration Service, like a futuristic moving company. It carefully transports your data to Azure SQL Database, a sleek skyscraper in our city. With minimal downtime, your database seamlessly transitions to its new home, ready to thrive amidst the azure skyline. Just sit back, relax, and watch as your data becomes part of the bustling digital metropolis.How do I ensure my database is highly resilient in this cosmic city?
In our cosmic city, resilience is key. Azure offers a robust solution: Azure SQL Database with built-in redundancy, akin to a fortress with multiple layers of defense. Automatic backups act as a safety net, ensuring data is never lost. Geo-replication creates duplicates across regions, safeguarding against disasters. With Azure SQL Database’s high availability and disaster recovery features, your database thrives amidst the azure skyline, resilient against any digital storm.I don’t know if it works for you but I find it fascinating I can make ChatGPT talk endlessly and respond to any questions I have about Azure in a sci-fi story!
Dive into an Azure componentAs usual with ChatGPT you need to drive the discussion to get the most of it. Let’s see what it has to say about Azure AD (I use the legacy terminology as ChatGPT v3.5 doesn’t know yet Microsoft Entra ID):
What and where would be the Azure AD in this city?
In our bustling city, Azure AD is the central hub, akin to City Hall. It’s where identities are registered, like citizens in our digital society. Located at the heart of the city, Azure AD ensures secure access to every digital service and resource, much like City Hall grants access to essential services. From authentication to authorization, Azure AD governs the city’s digital identities, ensuring a seamless and secure experience for all inhabitants amidst the azure skyline.How would Azure AD conditional access be implemented in this city?
In our city, Azure AD Conditional Access acts as the city’s security checkpoints. Picture futuristic gates at key entry points, only granting access to authorized individuals based on specific conditions. Want to enter the financial district skyscraper? You’ll need more than just a pass; perhaps a biometric scan during business hours. Conditional Access ensures only the right people, with the right permissions, access sensitive areas of our digital city. It’s our shield against cyber threats amidst the azure skyline, ensuring a safe and secure digital environment for all inhabitants.How would I connect from my Active Directory in the countryside to this Azure AD in the cloud?
In the countryside, your Active Directory (AD) is like a quaint village square, bustling with local identities. To connect to Azure AD in our cosmic cloud city, envision a digital bridge spanning the distance between village and skyline. Azure AD Connect is your trusty guide, seamlessly synchronizing identities from countryside AD to Azure AD. With this bridge in place, villagers can access digital services in the cloud using their familiar countryside credentials. Just like that, the countryside becomes an integral part of our digital metropolis, united under the azure skyline.You can then piece by piece for each component create a complete city in the countryside (OnPrem) and in the cloud and illustrate their interaction. We could completely gamify this! SimCity anyone?
LimitationsSome general concepts are more difficult to put into a visual story as for example the Microsoft Cloud Adoption Framework:
What would be the Microsoft Cloud Adoption Framework for Azure in this city?
In our dynamic metropolis, the Microsoft Cloud Adoption Framework for Azure is our roadmap to success. Like a futuristic GPS, it guides us through the twists and turns of digital transformation. Envisioning helps us set our destination, planning ensures we choose the best route, and readiness prepares us for the journey ahead. Migration helps us seamlessly transition, while innovation propels us forward. With governance as our compass and optimization as our fuel, we navigate the ever-changing landscape, building a future where our digital city thrives amidst the azure skyline. Ready to embark on this transformative journey?I don’t find it fantastic as we recognize the empty blabbering of ChatGPT. We would need to be more specific to get something more interesting.
Wrap upYou can see how by relaxing from your studies, you can still continue to learn by having fun in an imaginary world. You could totally convert all this into visual notes that will help you when you renew your certifications. That is something I’m starting to explore.
This is just a glimpse of how you could use ChatGPT in your journey to learn Azure or anything else. Brainstorm any concept, service or component you are learning and see how it integrates into a visual story to get a high-level picture. Let me know if your are using ChatGPT that way for learning and what is the world you are building for it!
L’article Learning Azure by having fun with ChatGPT est apparu en premier sur dbi Blog.
Monitor Elasticsearch Cluster with Zabbix
Setting up Zabbix monitoring over an Elasticsearch cluster is quiet easy as it does not require an agent install. As a matter a fact, the official template uses the Elastic REST API. Zabbix server itself will trigger these requests.
In this blog post, I will quick explain how to setup Elasticsearch cluster, then how easy the Zabbix setup is and list possible issues you might encounter.
Elastic Cluster SetupI will not go too much in detail as David covered already many topics around ELK. Anyway, would you need any help to install, tune or monitor your ELK cluster fell free to contact us.
My 3 virtual machines are provisioned with YaK on OCI. Then, I install the rpm on all 3 nodes.
After starting first node service, I am generating an enrollment token with this command:
/usr/share/elasticsearch/bin/elasticsearch-create-enrollment-token -node
This return a long string which I will need to pass on node 2 and 3 of the cluster (before starting anything):
/usr/share/elasticsearch/bin/elasticsearch-reconfigure-node --enrollment-token <...>
Output will look like that:
This node will be reconfigured to join an existing cluster, using the enrollment token that you provided.
This operation will overwrite the existing configuration. Specifically:
- Security auto configuration will be removed from elasticsearch.yml
- The [certs] config directory will be removed
- Security auto configuration related secure settings will be removed from the elasticsearch.keystore
Do you want to continue with the reconfiguration process [y/N]
After confirming with a y, we are almost ready to start. First, we must update ES configuration file (ie. /etc/elasticsearch/elasticsearch.yml).
- Add IP of first node (only for first boot strapped) in
cluster.initial_master_nodes: ["10.0.0.x"] - Set listening IP of the inter-node trafic (to do on node 1 as well):
transport.host: 0.0.0.0 - Set list of master eligible nodes:
discovery.seed_hosts: ["10.0.0.x:9300"]
Now, we are ready to start node 2 and 3.
Let’s check the health of our cluster:
curl -s https://localhost:9200/_cluster/health -k -u elastic:password | jq
If you forgot elastic password, you can reset it with this command:
/usr/share/elasticsearch/bin/elasticsearch-reset-password -u elastic
With latest Elasticsearch release, security has drastically increased as SSL communication became the standard. Nevertheless, default MACROS values of the template did not. Thus, we have to customize the followings:
- {$ELASTICSEARCH.USERNAME} to elastic
- {$ELASTICSEARCH.PASSWORD} to its password
- {$ELASTICSEARCH.SCHEME} to https
If SELinux is enabled on your Zabbix server, you will need to allow zabbix_server process to send network request. Following command achieves this:
setsebool zabbix_can_network 1
Next, we can create a host in Zabbix UI like that:
The Agent interface is required but will not be used to reach any agent as there are not agent based (passive or active) checks in the linked template. However, http checks uses HOST.CONN MACRO in the URLs. Ideally, the IP should be a virtual IP or a load balanced IP.
Don’t forget to set the MACROS:
After few minutes, and once nodes discovery ran, you should see something like that:
What will happen if one node stops? On Problems tab of Zabbix UI:

After few seconds, I noticed that ES: Health is YELLOW gets resolved on its own. Why? Because shards are re-balanced across running servers.
I confirm this by graphing Number of unassigned shards:
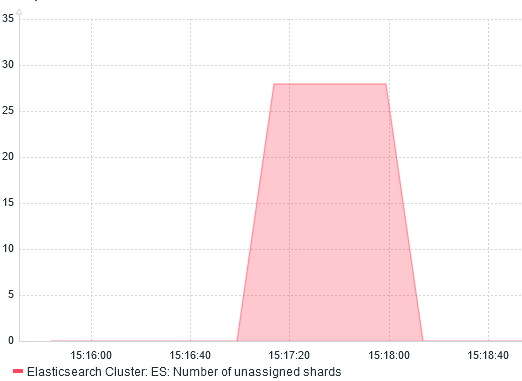
We can also see the re-balancing with the network traffic monitoring:
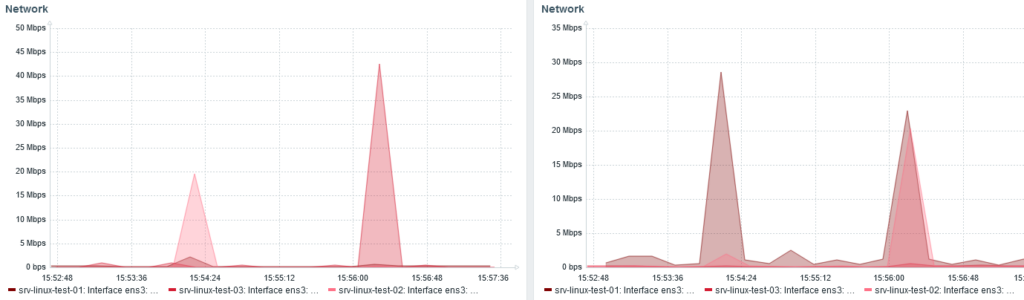 Received bytes on the left. Sent on the right.
Received bytes on the left. Sent on the right.
Around 15:24, I stopped node 3 and shards were redistributed from node 1 and 2.
When node 3 start, at 15:56, we can see node 1 and 2 (20 Mbps each) send back shards to node 3 (40 Mbps received).
ConclusionWhatever the monitoring tool you are using, it always help to understand what is happening behind the scene.
L’article Monitor Elasticsearch Cluster with Zabbix est apparu en premier sur dbi Blog.
Power BI Report Server: unable to publish a PBIX report
I installed a complete new Power BI Report Server. The server had several network interfaces to be part of several subdomains. In order to access the Power BI Report Server web portal from the different subdomains I defined 3 different HTTPS URL’s in the configuration file and a certificate binding. I used as well a specific active directory service account to start the service. I restarted my Power BI Report Server service checking that the URL reservations were done correctly. I knew that in the past this part could be a source of problems.
Everything seemed to be OK. I tested the accessibility to the Power BI Report Server web portal from the different sub-nets clients and everything was fine.
The next test was the upload of a Power BI report to the web portal. Of course I was sure, having a reports developed with Power BI Desktop RS.
Error raisedAn error was raised when uploading a Power BI report in the web portal.
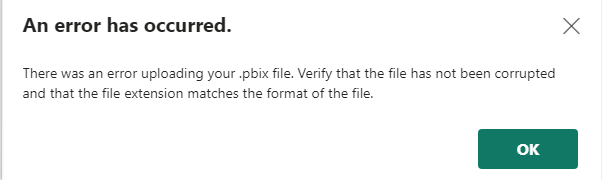
Trying to publish the report from Power BI Desktop RS was failing as well.
 Troubleshouting
Troubleshouting
Report Server log analysis:
I started to analyze the Power BI Report Server logs. For a standard installation they are located in
C:\Program Files\Microsoft Power BI Report Server\PBIRS\LogFiles
In the last RSPowerBI_yyyy_mm_dd_hh_mi_ss.log file written I could find the following error:
Could not start PBIXSystem.Reflection.TargetInvocationException: Exception has been thrown by the target of an invocation. ---> System.Net.HttpListenerException: Access is denied
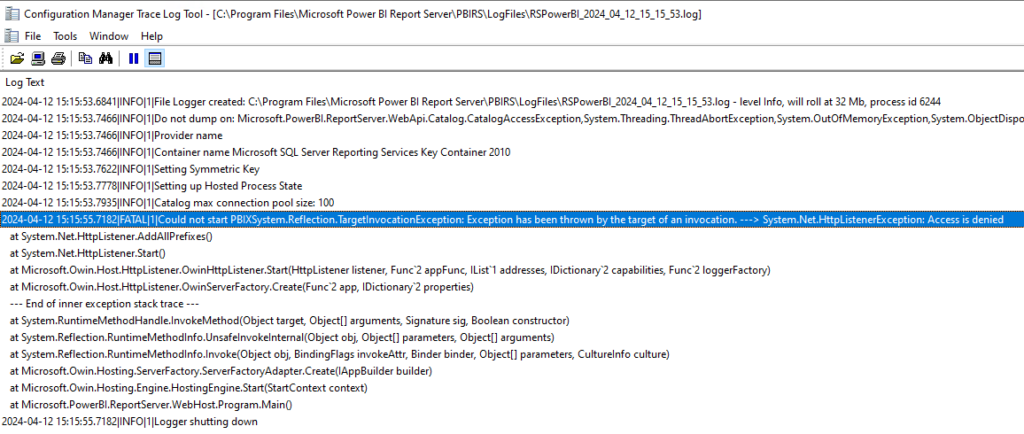
The error showing an Access denied, the first reaction was to put the service account I used to start the Power BI Report Server in the local Administrators group.
I restarted the service and tried again the publishing of the Power BI report. It worked without issue.
Well, I had a solution, but the it wasn’t an acceptable one. A application service account should not be local admin of a server, it would be a security breach and is not permitted by the security governance.
Based on the information contained in the error message, I could find that is was related to URL reservation, but from the configuration steps, I could not notice any issues.
I analyzed than the list of the reserved URL on the server. Run the following command with elevated permissions to get the list of URL reservation on the server:
Netsh http show urlacl
List of URL reservation found for the user NT SERVICE\PowerBIReportServer:
Reserved URL : http://+:8083/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub1.domain.com:443/ReportServerPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub2.domain.com:443/ReportServerPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/PowerBI/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/wopi/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub1.domain.com:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://sub2.domain.com:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Reserved URL : https://servername.domain.com.ch:443/ReportsPBIRS/
User: NT SERVICE\PowerBIReportServer
Listen: Yes
Delegate: No
SDDL: D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)
Checking the list I could find:
- the 3 URL’s reserved fro the web service containing the virtual directory I defined ReportServerPBIRS
- the 3 URL’s reserved fro the web portal containing the virtual directory I defined ReportsPBIRS
But I noticed that only 1 URL was reserved for the virtual directories PowerBI and wopi containing the servername.
The 2 others with the subdomains were missing.
SolutionI decided to reserve the URL for PowerBI and wopi virtual directory on the 2 subdomains running the following command with elevated permissions.
Be sure that the SDDL ID used is the one you find in the rsreportserver.config file.
netsh http add urlacl URL=sub1.domain.com:443/PowerBI/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub2.domain.com:443/PowerBI/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub1.domain.com:443/wopi/ user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
netsh http add urlacl URL=sub2.domain.com:443/wopi// user="NT SERVICE\SQLServerReportingServices" SDDL="D:(A;;GX;;;S-1-5-80-1730998386-2757299892-37364343-1607169425-3512908663)"
Restart the Power BI Report Server service
You can notice that the error in the latest RSPowerBI_yyyy_mm_dd_hh_mi_ss.log file desappeared.
I tested the publishing of a Power BI report again, and it worked.
I hope that this reading has helped to solve your problem.
L’article Power BI Report Server: unable to publish a PBIX report est apparu en premier sur dbi Blog.
PostgreSQL 17: pg_buffercache_evict()
In PostgreSQL up to version 16, there is no way to evict the buffer cache except by restarting the instance. In Oracle you can do that since ages with “alter system flush buffer cache“, but not in PostgreSQL. This will change when PostgreSQL 17 will be released later this year. Of course, flushing the buffer cache is nothing you’d usually like to do in production, but this can be very handy for educational or debugging purposes. This is also the reason why this is intended to be a developer feature.
For getting access to the pg_buffercache_evict function you need to install the pg_buffercache extension as the function is designed to work over the pg_buffercache view:
postgres=# select version();
version
-------------------------------------------------------------------
PostgreSQL 17devel on x86_64-linux, compiled by gcc-7.5.0, 64-bit
(1 row)
postgres=# create extension pg_buffercache;
CREATE EXTENSION
postgres=# \dx
List of installed extensions
Name | Version | Schema | Description
----------------+---------+------------+---------------------------------
pg_buffercache | 1.5 | public | examine the shared buffer cache
plpgsql | 1.0 | pg_catalog | PL/pgSQL procedural language
(2 rows)
postgres=# \d pg_buffercache
View "public.pg_buffercache"
Column | Type | Collation | Nullable | Default
------------------+----------+-----------+----------+---------
bufferid | integer | | |
relfilenode | oid | | |
reltablespace | oid | | |
reldatabase | oid | | |
relforknumber | smallint | | |
relblocknumber | bigint | | |
isdirty | boolean | | |
usagecount | smallint | | |
pinning_backends | integer | | |
Once the extension is in place, the function is there as well:
postgres=# \dfS *evict*
List of functions
Schema | Name | Result data type | Argument data types | Type
--------+----------------------+------------------+---------------------+------
public | pg_buffercache_evict | boolean | integer | func
(1 row)
To load something into the buffer cache we’ll make use of the pre_warm extension and completely load the table we’ll create afterwards:
postgres=# create extension pg_prewarm;
CREATE EXTENSION
postgres=# create table t ( a int, b text );
CREATE TABLE
postgres=# insert into t select i, i::text from generate_series(1,10000) i;
INSERT 0 10000
postgres=# select pg_prewarm ( 't', 'buffer', 'main', null, null );
pg_prewarm
------------
54
(1 row)
postgres=# select pg_relation_filepath('t');
pg_relation_filepath
----------------------
base/5/16401
(1 row)
postgres=# select count(*) from pg_buffercache where relfilenode = 16401;
count
-------
58
(1 row)
If you wonder why there are 58 blocks cached in the buffer cache but we only loaded 54, this is because of the visibility and free space map:
postgres=# select relforknumber from pg_buffercache where relfilenode = 16401 and relforknumber != 0;
relforknumber
---------------
1
1
1
2
(4 rows)
Using the new pg_buffercache_evict() function we are now able to completely evict the buffers of that table from the cache, which results in exactly 58 blocks to be evicted:
postgres=# select pg_buffercache_evict(bufferid) from pg_buffercache where relfilenode = 16401;
pg_buffercache_evict
----------------------
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
t
(58 rows)
Cross-checking this confirms, that all the blocks are gone:
postgres=# select count(*) from pg_buffercache where relfilenode = 16401;
count
-------
0
(1 row)
Nice, thanks to all involved.
L’article PostgreSQL 17: pg_buffercache_evict() est apparu en premier sur dbi Blog.